Jekyll2025-04-18T20:25:05+02:00https://chciken.com/feed.xmlchcikenThis is my website :)TLMBoy: The Audio Processing Unit (APU) - Square Channel2025-03-28T15:51:44+01:002025-03-28T15:51:44+01:00https://chciken.com/tlmboy/2025/03/28/gameboy-apu-squareIn this part of my Game Boy simulator post series, I will cover the details of the square channel of the so-called Audio Processing Unit (APU).
Unlike modern hardware, the Game Boy cannot (or is not supposed) to play black sample-based audio recordings.
Rather the APU has 4 different channels that act like instruments controlled by notes and dynamics.
Two of these channels are square channels, which are the focus of this post.
These channels generate square waves at given frequencies allowing you to play notes just like an instrument.
The first square channels also has some extra frequencies-shifting features, which can be used to create various kinds of sounds.
When it comes to information about the Game Boy’s hardware, there’s already plenty information available.
The following sources helped me a lot to write this post and my Game Boy simulator:
Unlike the technical documentation from above, this post follows a more example-driven approach.
So, rather than getting lost in every tiny obscure behavior, I first highlight the general principles of the square channel, which is then followed by some practical examples on how games made use of it.
I also provide a test ROM, which can be used for testing in emulator/simulator development.
Similar to other units of the Game Boy (DMA, Pixel Processing Unit, etc.), communication with the APU is facilitated by
memory-mapped I/O.
That means if you want to tell the APU something you just write something into certain memory-mapped registers,
while information about the APU’s current status can retrieved by reading these registers.
For the two square channels, the following registers are relevant:
Square 1:
Name
Address
Bits
Function
NR10
0xFF10
-PPP NSSS
Sweep period, negate, shift
NR11
0xFF11
DDLL LLLL
Wave duty, length load
NR12
0xFF12
VVVV EPPP
Init volume, envelope mode, envelope period
NR13
0xFF13
FFFF FFFF
Frequency LSB
NR14
0xFF14
TL-- -FFF
Trigger, length enable, frequency MSB
Square 2:
Name
Address
Bits
Function
NR21
0xFF16
DDLL LLLL
Wave duty, length load
NR22
0xFF17
VVVV EPPP
Init volume, envelope mode, envelope period
NR23
0xFF18
FFFF FFFF
Frequency LSB
NR24
0xFF19
TL-- -FFF
Trigger, length enable, frequency MSB
Since Square 2 has a subset of the features of Square 1, the following only highlights the details of Square 2.
Except for the missing features (sweep period, negate, shift), Square 1 and Square 2 work similarly.
Square Channels
The square wave channel allows you to play - big surprise - square waves.
This kind of wave truly defines the Game Boy’s chiptune sound.
And since this channel is so important, the Game Boy allows you two play two square waves at the same time!
While many synthesizers allow you to heavily modify the square wave, the Game Boy’s options are very limited in that regard.
Anyway, first the very technical definition of the square wave channel register before we are heading to some examples.
NR10: Channel Sweep
The sweep channel can be used to change the frequency of the square wave over time.
This is primarily used to model sound effects, such as hopping on a Goomba in Super Mario Land.
[0:2] 3-bit step: Each iteration, a new frequency is calculated as: F(i+1) = F(i) + F(i) / 2^step.
This value is also written back to register NR13 and NR14! [3:3] 1-bit direction: 0 → frequency increase, 1 → frequency decrease. [4:6] 3-bit period: The sweep is updated every (period * 7.8 milliseconds). A value of 0 disables the sweep.
NR11: Channel Length Timer & Duty
[0:5] 6-bit initial length timer:
Can be read from or written to.
The 6 bits are interpreted as an unsigned number ranging from 0 to 63.
This number determines the length of the sound: length = (64-value)*(1/256) seconds.
So, the shortest sound is 1/256 second, while the longest is 1/4 second.
Note that the “64-value” part leads to some counterintuitive behavior.
When writing 0, you get the longest possible length, an when writing 63, you get the shortest possible length.
If you want indefinite sustain, disable Bit 6 in register NR44. [6:7] 2-bit duty cycle: Determines the duty cycles of the square wave (00 → 12.5%, 01 → 25%, 10 → 50%, 11 → 75%).
Note that 25% and 75% give the same audible impression when the square wave is played without the other channels.
NR12: Channel Volume & Envelope
[0:2] 3-bit Envelope update period: The envelope ticks at 64 Hz, and the channel’s volume is updated every Nth (given by 3-bit value) tick.
So, the fastest possible update is 64 Hz, while the slowest 8Hz. 0 disables the envelope. [3:3] 1-bit envelope mode: 0 → decrement volume, 1 → increment volume. [4:7] 4-bit initial volume: Starting volume representing values between 0-15. You can read these bits but the hardware does not update them!
NR13: Frequency LSB
[0:7] 8-bit frequency lower bits: The frequency comprises 11 bits in total (see NR14).
The square channel uses a non-exposed, 11-bit counter that increases every time it is clocked.
After 2047 it overflows, generates a signal, and is set to the value of NR13 and NR14.
The resulting frequency is: 131,072/(2048-frequency).
Hence, the lowest frequency is 64 Hz and highest ones is 131,072 Hz, which is already far out of the reach humans can hear.
NR14: Channel Control & Frequency MSB
[0:2] 3-bit frequency lower bits: Upper bits of the period. See NR13. [6:6] 1-bit length enable:
0 = Regardless of the length data in NR14 sound can be produced consecutively.
1 = Sound is generated during the time period set by the length data in NR14.
After this period the sound 1 ON flag (bit 0 of NR52) is reset. [7:7] 1-bit trigger (write-only): Writing 1 to this bit causes the following things:
The square channel is enabled. If the length timer expired it is reset. Envelope timer is reset.
Volume is set to contents of NR41 initial volume. The period divider is set to the contents of NR13 and NR14. Sweep does things.
Square Simulator
Here’s a Javascript-based square channel simulator.
In the table below you can setup individual fields and listen to the sound they would create on the Game Boy.
Note that the simulator repeats every 2 seconds.
Predefined setups of some games are provided in the next section.
Register
Setting
NR10: Channel Sweep
Step
Direction
Period
NR11: Length Timer
Length
Duty
NR12: Envelope
Volume
Envelope mode
Envelope period
NR13/NR14: Square Frequency
Frequency
NR13: Channel Control
Length enable:
Besides an implementation in Javascript, I also wrote the same application for the Game Boy:
In the following, examples of square channel in real-world software are provided.
Click on “Use this setup” to load the square simulator with the corresponding setup.
Boot
One simple, yet iconic example of the square wave is the Game Boy’s boot sound.
From examining the boot code (see also my boot ROM post), I found the two following register settings:
NR10: 0000 0000 -> No sweep
NR11: 1000 0000 -> Duty cycle 50%, length irrelevant due to NR14
NR12: 1111 0011 -> Full volume, decrement volume, update envelope every 3 envelope ticks
NR13: 1000 0011 -> Frequency: 1048.576 Hz (C6)
NR14: 1000 0111 -> Trigger, sound indefinite length, period upper 3 bits
NR10: 0000 0000 -> No sweep
NR11: 1000 0000 -> Duty cycle 50%, length irrelevant due to NR14
NR12: 1111 0011 -> Full volume, decrement volume, update envelope every 3 envelope ticks
NR13: 1100 0001 -> Frequency: 2080.50 Hz (C7)
NR14: 1000 0111 -> Trigger, sound indefinite length, period upper 3 bits
So, a very simple square with 50% duty and no fancy sweep settings.
The sound starts at full volume and is then decremented every 3 envelope ticks.
If I did the math correctly, that should correspond to a length of ~0.7s until the volume reaches 0.
Note that the Game Boy plays two sounds to get this “bling bling.”
First a C6, which is only played for four frames (~66 milliseconds), and then a C7, which is played for the full duration of ~0.7 seconds.
Super Mario Land
In Super Mario Land I found a few examples that make use the square’s sweep setting to model sound effects.
Note that sound effects may involve multiple subsequent setting.
In the following only single settings are provided.
When jumping on a Goomba, you get the following setting:
NR10: 0101 0111 -> step = 7, frequency increase, sweep period = 5
NR11: 1000 0000 -> duty = 2%, length = 0 (irrelevant due to NR14)
NR12: 0110 0010 -> envelope period = 2, decrement volume, volume = 6
NR13: 0000 0110 -> frequency = 1798
NR14: 1000 0111 -> trigger, sound indefinite length
Parts of the sound when taking a mushroom are very similar to the Goomba sound:
]]>TLMBoy: The Audio Processing Unit (APU) - Noise Channel2025-03-24T13:22:44+01:002025-03-24T13:22:44+01:00https://chciken.com/tlmboy/2025/03/24/gameboy-apu-noiseIn this part of my Game Boy simulator post series, I will cover the details of the noise channel of the so-called Audio Processing Unit (APU).
Unlike modern hardware, the Game Boy cannot (or is not supposed) to play black sample-based audio recordings.
Rather the APU has 4 different channels that act like instruments controlled by notes and dynamics.
One of these channels is the noise channel.
It’s quite versatile and can be used to resemble snares, hi-hats, explosions, or even waves washing up on shore.
When it comes to information about the Game Boy’s hardware, there’s already plenty information available.
The following sources helped me a lot to write this post and my Game Boy simulator:
To not write yet another technical documentation like the sources above, this post follows a more example-driven approach.
So, rather than getting lost in every tiny obscure behavior, I first highlight the general principles of the noise channel, which is then followed by some practical examples on how games made use of it.
I also provide a test ROM, which can be used for testing in emulator/simulator development.
Similar to other units of the Game Boy (DMA, Pixel Processing Unit, etc.), communication with the APU is facilitated by
memory-mapped I/O.
That means if you want to tell the APU something you just write something into certain memory-mapped registers,
while information about the APU’s current status can retrieved by reading these registers.
For the noise channel, the following 4 registers are relevant:
Name
Address
Bits
Function
NR41
0xFF20
--LL LLLL
Length load
NR42
0xFF21
VVVV APPP
Starting volume, envelope mode, period
NR43
0xFF22
SSSS WDDD
Clock shift, width mode of LFSR, divisor code
NR44
0xFF23
TL-- ----
Trigger, length enable
In the following these registers are described in greater detail.
NR41: Length Timer
This register is used to control the length of a sound.
In musical terms, this refers to a note’s duration.
The register has only one field, controlling the length of a sound as follows:
[0:5] 6-bit length load: Can be read from or written to.
The 6 bits are interpreted as an unsigned number ranging from 0 to 63.
This number determines the length of the sound: length = (64-value)*(1/256) seconds.
So, the shortest sound is 1/256 second, while the longest is 1/4 second.
Note that the “64-value” part leads to some counterintuitive behavior.
When writing 0, you get the longest possible length, an when writing 63, you get the shortest possible length.
If you want indefinite sustain, disable Bit 6 in register NR44.
NR42: Envelope
The envelope register is used to control the volume envelope of a sound.
The volume envelope describes how the volume of a sound changes over time.
For example, a decreasing envelope can be used to mimic some kind of decay as with pianos or guitars.
The register comprises 3 fields:
[0:2] 3-bit envelope period:
Interpreted as a 3-bit unsigned integer (0-7).
Determines how often the envelope is updated.
A decrement/increment happens every period*(1/64) second.
Writing 0 disables the envelope. [3:3] 1-bit envelope add mode:
0 → decrement volume, 1 → increment volume. [4:7] 4-bit starting volume of the envelope:
Represents a starting volume between 0-15.
The value is incremented/decremented depending on the envelope mode and period.
Important: You can read these bits but the hardware does not update them!
NR43: Noise Shape
This register is used to control the noises’s shape/color.
Depending on the settings you can create everything from white noise to high-pitched metallic sounds.
To create pseudo-random numbers for the noise channel, the Game Boy uses a Linear-Feedback Shift Register (LFSR):
Each time the LFSR is ticked, it performs the following three steps:
The low two bits (0 and 1) are XORed and negated.
The result of the XOR is put into the now-empty high bit (either Bit 15 or Bit 7 depending on the mode).
All bits are shifted right by one.
The frequency by which new values are generated is: 4.194304 MHz / ( divider « shift),
whereby divider is in {8, 16, 32, 48, 64, 80, 96, 112}, and shift is between 0 and 13.
Hence, the highest frequency is 524,288 MHz and the lowest frequency is 4.57 Hz.
Divider, width mode, and clock shift are derived from the following fields:
[0:2] 3-bit divider: Interpreted as a 3-bit unsigned integer (0-7). See formula. [3:3] 1-bit width mode: Width of the LFSR. 0 → 15 bit, 1 → 7 bit. [4:7] 4-bit clock shift: Interpreted as a 4-bit unsigned integer (0-15). See formula.
According to the programmer manual, the values 14 and 15 are illegal. Interestingly, this constraint is not mentioned in all documentation you can find online.
The LFSR has some interesting properties that I want to highlight in greater detail.
For instance, in 7-bit mode, the generated pattern repeats every 127 cycles.
In case you want to see it yourself, use this python script:
Interestingly, the only value a 7-bit LFSR never reaches is all bits being 1.
This is for a good reason, as such a value would lock the LFSR permanently in this state, resulting in only 1s being generated for the output.
In practice it’s actually possible to arrive in such a situation, when switching from 15-bit mode to 7-bit in the right moment.
NR44: Channel Control
The channel control register only comprises two 1-bit fields:
[6:6] 1-bit length enable:
0 → Regardless of the length data in NR41 sound can be produced consecutively.
1 → Sound is generated during the time period set by the length data in NR41.
After this period the sound 4 ON flag (bit 3 of NR52) is reset. [7:7] 1-bit trigger (write-only): Writing 1 to this bit causes the following things:
The noise channel is enabled. If the length timer expires it is reset. Envelope timer is reset.
Volume is set to contents of NR42 initial volume. LFSR bits are reset.
Noise Simulator
After all these technical details, it’s time for some practical evaluation.
To get a better understanding of how the individual register and their fields are playing together in practice, I wrote a Javascript-based noise simulator.
In the table below you can setup individual fields and listen to the sound they would create on the Game Boy. Note that the simulator repeats every 2 seconds.
Predefined setups of some games are provided in the next section.
Tetris Hi-hat:
NR41: 0011 1010 -> 58 -> length = 1/42 s (~23 ms)
NR42: 1010 0001 -> Envelope: Decrement every 1/64s (~16ms), starting from volume 10
NR43: 0000 0000 -> 15-bit LFSR, divisor 8, shift 0 (524,288 Hz)
NR44: 1100 0000 -> Sound according to length
Tetris Snare:
NR41: 0010 1001 -> 41 -> length = 23/264 s (~90 ms)
NR42: 1011 0001 -> Envelope: Decrement every 1/64s (~16ms), starting from volume 11
NR43: 0000 0001 -> 15-bit LFSR, divisor 16, shift 0 (262,144 Hz)
NR44: 1100 0000 -> Sound according to length
The first setting is used for something hi-hat-like sound, while the other one is used for a snare.
As you can see and hear, they are not too different.
The snare has a slightly higher starting volume, a greater length, and uses a higher divisor.
All of that doesn’t really change the color of the sound but makes the snare more dominant compared to the hi-hat.
Super Mario Land
When defeating a Bombshell Koopa in Super Mario Land, the noise channel is used to create a sound of an explosion.
Bombshell Koopa Explosion:
NR41: 0000 0000 -> 0 -> length = 64/256 s (250 ms)
NR42: 1111 0100 -> Envelope: Decrement every 4/64s (~62.5ms), starting from volume 15
NR43: 0101 0111 -> 15-bit LFSR, divisor 112, shift 5 (1170.3 Hz)
NR44: 1000 0000 -> Sound not according to length
In comparison to the settings in Tetris, Super Mario Land does not use the length register, as this would limit the sound to 250 ms at most.
By only relying on the decrement register, it takes roughly 1 second for the sound to go from volume 15 to volume 0.
With an LFSR sample rate of 1170.29 Hz, the noise is also very chiptune-like.
So far, all examples used a 15-bit LFSR. This is not very surprising as 7-bit provides very little randomness.
In fact, the 127-cycle repetition gives it a metallic high-pitched sound for higher LFSR sample rates, which is very far away from being white noise.
This can be heard in parts of the sound that are played when defeating a Fighter Fly:
Fighter Fly Defeated:
NR41: 0000 0000 -> 0 -> length = 64/256 s (250 ms)
NR42: 0010 1100 -> Envelope: Increase every 4/64s (~62.5 ms), starting from volume 2
NR43: 0001 1110 -> 7-bit LFSR, divisor 96, shift 1 (21,845.3 Hz)
NR44: 1000 0000 -> Sound not according to length
Note that this only a part of the sound when defeating a Fighter Fly. Some of the registers are altered after a short period of time to make the sound more insect-like.
Bomberman GB
For lower LFSR sample rates, the sound of a 7-bit LFSR gets “noisier” and somewhat approximates the sound of a 15-bit LFSR.
Nevertheless, the 127-cycle repetition leads to some kind of reverb effect.
The exploding bombs in Bomberman GB are a good example of an explosion sound with a touch of reverb.
Bomb explosion:
NR41: 1111 0111 -> 0 -> length = 55/256 s (214 ms)
NR42: 1110 0101 -> Envelope: Decrease every 5/64s (~78.1 ms), starting from volume 14
NR43: 0110 1011 -> 7-bit LFSR, divisor 48, shift 6 (87,381.3 Hz)
NR44: 1000 0000 -> Sound not according to length
The Legend Of Zelda: Link’s Awakening
Another example showcasing the great versatility of the noise channel can be found in the intro of The Legend Of Zelda: Link’s Awakening.
Here, a fading white noise sound is used to mimic the waves washing up on shore.
Wave fading in:
NR41: 0000 0000 -> 0 -> length = 64/256 s (250 ms)
NR42: 0000 1111 -> Envelope: Increase every 7/64s (~109.4 ms), starting from volume 0
NR43: 0011 0000 -> 15-bit LFSR, divisor 8, shift 3 (65,536 Hz)
NR44: 1000 0000 -> Sound not according to length
Wave fading out:
NR41: 0000 0000 -> 0 -> length = 64/256 s (250 ms)
NR42: 0110 0111 -> Envelope: Decrease every 7/64s (~109.4 ms), starting from volume 6
NR43: 0000 0011 -> 15-bit LFSR, divisor 48, shift 0 (87,381.3 Hz)
NR44: 1000 0000 -> Sound not according to length
]]>The Jungle Book (Game Boy) : A Complete Guide2024-10-27T15:22:44+01:002024-10-27T15:22:44+01:00https://chciken.com/gaming/2024/10/27/jungle-book-gameboyNow to a project into which I invested way too much time: A Complete Guide for the Game Boy’s “The Jungle Book” game.
By complete I mean two things.
First, a very detailed guide on how to play through the game. To the best of my knowledge, there is no such guide available on the internet.
In fact, there seems to be only very little information about the game at all.
Second, my journey of reverse engineering the game.
In order to understand every bit of the game, I reverse engineered the game and created a disassembly.
Many of the results, such as the level maps, were used for the walkthrough guide.
The Github repository is available as open source..
The game “The Jungle Book” was actually released for multiple platforms in 1994 with the Game Boy version being the technically most limited.
It is a very classic platformer that doesn’t really have much to offer from a game-play perspective.
There’s just running, jumping, and defeating enemies - everything underpinned with rather sluggish controls and awkward hit boxes.
The graphics are quite neat for a Game Boy game, but the frequently dropping frame rate is really stressful for the eye.
So, overall a pretty mediocre 90s Game Boy game.
Although the UK-based video game magazine “Computer and Video Games” Issue 150 from May 1994 gave it a solid 87/100 score (see page 91):
I guess the publishers/developers put everything on the Disney card - a typical pathology of franchise games.
The only outstanding thing was the game’s insane difficulty.
It’s still etched into my mind how I was never able to get past Level 2.
In the 90s I was still very young and far away from my gaming skill all-time high, so almost 25 years later (and exactly 30 years after the game’s release!) I decided to update my conclusion.
Even with more experience and skill I have to admit: the game is hard.
While the levels become manageable with some training, the lack of save state is really annoying.
In order to complete the game, you need to finish the 10 levels without having the chance to save even once.
With the former speedrun record in practice mode already requiring 27 minutes, I really can’t imagine how little children are supposed to beat the game.
But if you really bring the perseverance and motivation to defeat the game, having a plan helps a lot.
Because most of the time, your objective is to collect gems, which are sprinkled across the map.
If you know where these gems are, the game becomes way more easier.
And this is why I wrote this guide.
So, if you also want to overcome your childhood trauma of an unbeaten Jungle Book Game Boy game, you have come to the right place.
In the following, I will first list general details about the game, which is then succeeded by a per-level guide.
For every level, I created three different maps from the ROM.
First, the plain map extracted from the ROM.
Second, an annotated map with gem and enemy locations.
Third, a map for a practice mode speed run.
History
Since mere gameplay facts about a 30-year-old Game Boy game are perhaps a little too dull,
I added a chapter about the hopefully exciting story of the game’s development and some other curious facts.
As with most things, a fair starting point might be the Wikipedia article of the game.
Wikipedia mentions that Virgin Games (later renamed to Virgin Interactive Entertainment) started the development of the Genesis/Mega Drive version in 1993, and the game was intended to be delivered in the same year.
It is not clear from the Wikipedia article why Virgin Games developed this particular game.
However, if you look at the Virgin Games release list,
you quickly get the impression that Virgin Games worked through one franchise after the next.
So far, they had published games including Aladdin,
The Terminator,
Dune, Alien, and McDonald’s.
I guess “The Jungle Book” game was just next on the list.
However, the development lead David Perry including most of his team left Virgin Games during the game’s development.
Subsequently, the Genesis version was completed by Eurocom Entertainment Software.
They probably completed the Game Boy version too, as the starting screen and credit screen mention Eurocom as the developer:
After its completion, the game could finally be found in stores in 1994, where it was released for Genesis, Master System, SNES, NES, and Game Boy.
Although the serial number of the cartridge (DMG-J7-USA, DMG-J7-USA-1, DMG-J7-EUR, …) as well as the package and instruction booklet differed between regions,
all games use the same binary with English language output.
I actually own several different versions and the instruction booklets in particular are very different.
The booklet of the first US version (DMG-J7-USA) is particularly outstanding:
As you can see at first glance, the quality of the backgrounds and screenshots used is miserable (it’s not my scanner’s fault 😉).
At first, I thought I had bought a fake copy, but after some investigation, I came to a different conclusion:
Whoever designed the instruction booklet didn’t have sufficient information or wasn’t very commited.
Because the poor picture quality is not the only flaw.
If you read through the instruction booklet, you quickly realize that many of the things mentioned, such as 3 difficulties, don’t seem to be apply.
The screenshots shown don’t match the game either.
But if you know the NES version of the game, you will notice that content of the NES instruction booklet has been adopted here without much thought.
As a next point, let us move to the game’s perception.
When the game was released, the internet was still in its infancy, so any reviews from that time come from gaming magazines.
In total, I found five reviews from five magazines. Here’s what they say:
UK-based video game magazine Computer and Video Games Issue 150 from May 1994.
Score: 87/100 score.
Pro: Gem system gives the game some exploration depth. Nice graphics.
Cons: Enemies are too weak.
A German article from Video Games from June 1994.
Score: 80/100.
Pro: Good graphics. Good animations. Diverse and detailed levels.
Con: Background too lavish.
Another German article from Total! from April 1994.
I couldn’t find a copy online, so I bought an original print from ebay.
Score: 2. They use a grading system similar to the German school grading system. With a “2”, the game is among the best 3 games out of 12 in the magazine’s issue.
Pro: Nice animation and soundtrack.
Con: Levelcodes missing.
Article from from British Total! Nintendo Magazin from April 1994.
Score: 90/100.
Pro: Good graphics. Good animations. Positive feeling of control.
Con: More contrasting background would be great. The game overreaches itself.
A French article from SUPWER POWER from March 1994.
My French is a bit rusty, so I asked ChatGPT to translate the article.
It’s not really a review but more like a description with some visual impressions.
Apparently, there’s a more detailed review following (“À suivre…” -> “To be continued…”), but I wasn’t able to find anything.
On average, this gives a score of (87/100 + 80/100 + 90/100) / 3 = 86/100.
So, a pretty good score. But maybe too good?
I mean the game is nice to look at (given a constant frame rate), but an average 86/100 score somehow feels unjustified.
Also, many of the negative points can be interpreted as positive points in disguise.
Like the background being too lavish, or the game trying to overreach itself.
Another thing that is slightly off is the number of mentioned levels.
Four of the magazines wrote about the gaming having 12 levels.
Well, in theory there are 12 levels, but one is a bonus level, and another one is just a transition animation.
Especially the latter cannot be really counted as level.
Also, the mentioned number of continues is off in two magazine (mentioned 2 and 3, 4 or 6 in practice), as well as the size of the cartridge (1 MiB mentioned, 128 kiB in practice).
It feels like someone sent these magazines some predetermined scores and information.
But well, maybe my feeling is just wrong and I’m the only person who doesn’t consider the game to be highly outstanding.
That’s why I tried to find independent user reviews on the net.
You can’t find many user-written reviews of the game, but I was able to find three. Here’s their conclusion:
User review 1 from 2022 gave it a 7/10.
Pro: Good graphics.
Con: Not much variation among levels. Stiff controls. Awkward floor hitbox. Annoying leaps of faith. Time limit too strict.
User review 2 from 2020 gave it 48/100.
Pro: Good graphics.
Con: Not knowing what to do. No hints for the gems. Awkware movement. Too much blurring.
User review 3 from 2006 gave it a 5/10.
Pro: Nothing.
Con: Not knowing what to do. Annoying when the last item cannot be found.
The user reviews all agree on the same facts: the game’s graphics are nice to look at, but the awkward gem collecting system with the stiff controls ruins the game.
On average, this gives a score of (70/100 + 48/100 + 50/100) / 3 = 56/100.
So, quite a contrast to the 86/100 average score of the gaming magazines.
I’m currently doing further investigations and will update this section from time to time.
But for now, that’s it!
Basic Game Facts
Gameplay
The game comprises 10 levels that have to be defeated in order to reach the credit screen.
You cannot save. If you want to beat the game, you have to beat all levels in one session.
In the start menu you can set the game to practice mode (it should rather be “easy mode” IMHO) by pressing SELECT. I highly recommend this mode.
In order to finish a level you need to collect all gems (7 in practice mode and 10 in normal mode). Only for Level 8 (FALLING RUINS) collecting a single gem is sufficient.
Some levels additionally require you to meet/defeat characters such as Kaa or Baloo.
You have 5 minutes of time to finish a level.
Mowgli has 52 health points.
All enemies deal 4 damage per hit in normal mode and 2 damage in practice mode.
Water deals continuous damage, independent of the chosen mode.
You have 6 lifes.
You have 4 continues in normal mode and 6 continues in practice mode.
Controls
Press SELECT in the start menu to toggle difficulty modes .
Press SELECT in the game to switch between different items/weapons.
Press START to (un)pause the game.
Use the D-pad to control Mowgli.
Press A to jump.
Press B to shoot projectiles and run faster.
If you press A+B+START+SELECT, the game will be restarted.
Items
The following items can be found across the map or are dropped by enemies:
Boomerang : A boomerang that can be used as a weapon.
Double banana : A double banana that can be used as a weapon.
Extra life : Collect Mowgli’s head to get an extra life.
Extra time : Gives some extra time when collected (1 minute in normal, 2 minutes in practice).
Extra level : If you collect the shovel, there will be a bonus level before the next level to collect additional items.
Flower : Activates a checkpoint when walking through the flower.
Gem : Collect gems to beat a level.
Grapes : Fills up your health bar when collected.
Leaf : Can only be collected in the bonus level. Grants an additional continue.
Medicine man mask : Grants invulnerability if selected as a weapon.
Pineapple : Just gives some extra points.
Stones : Stones that can be used as a weapon.
Weapons
There are 5 different weapons/items the player can use:
Banana (Index 0): Default weapon. Unlimited.
Double Bananas (Index 1): 0 by default. Dropped by enemies.
Boomerang (Index 2): 0 by default. Dropped by enemies.
Stones (Index 3): 0 by default. Dropped by enemies.
Mask (Index 4): 0 by default. Dropped by enemies. Grants you invincibility for a given time. During invincibility you shoot your default bananas.
The damage of the weapons (except for the default banana) is calculated as follows:
Note that the double banana may hit a target twice (once with each individual banana) leading to twice the damage.
The Levels
Level 1 (JUNGLE BY DAY)
The first, and probably most simple level, plays in the jungle by day.
I think there is no real association the with the movie’s plot and it just serves as a introduction.
The gimmick of this level is a catapult.
With a tool-assisted replay, the level can be beaten in 0:42.
width x height (in pixels): 3072 x 512
Items:
1x bonus level
1x boomerang
1x double banana
2x extra lifes
2x mask
0x stones
2x time
Passing Criteria:
Collect all gems
Level 2 (THE GREAT TREE)
The second level takes place at the Great Tree, in which Kaa resides.
In the game, there’s pretty much no plot, but I guess this is the point in the movie where Mowgli and Bagheera meet Kaa for the first time.
After collecting all gems you still have to defeat Kaa in some kind of boss battle at the end of the level.
The gimmick in this level are some kind of elevators in the tree’s stem.
With a tool-assisted replay, the level can be beaten in 1:00.
width x height (in pixels): 768 x 2048
Passing Criteria:
Collect all gems
Defeat Kaa
Level 3 (DAWN PATROL)
After the encounter with Kaa, Mowgli meets Colonel Hathi and his dawn patrol.
The dawn patrol also represents this level’s gimmick: A walking elephant herd that can be used as a platform.
With a tool-assisted replay, the level can be beaten in 0:50.
width x height (in pixels): 5376 x 320
Items:
1x bonus level
1x boomerang
0x double banana
0x extra lifes
1x mask
0x stones
0x time
Passing Criteria:
Collect all gems
Level 4 (BY THE RIVER)
This is the first level where you encounter water.
Being in the water progressively reduces your health until you die.
Unfortunately, the invincibility mask does not work against water.
I would say that this is one of the harder levels as falling into the water may happen frequently.
At the end of this level, you have to defeat Baloo.
With a tool-assisted replay, the level can be beaten in 1:02.
width x height (in pixels): 4096 x 512
Items:
1x bonus level
2x boomerang
0x double banana
1x extra lifes
0x mask
3x stones
1x time
Passing Criteria:
Collect all gems
Defeat Baloo
Level 5 (IN THE RIVER)
Loosely following the plot of the movie, Mowgli is floating down the river on Baloo.
Interestingly, you can shorten the level significantly by using one of the fishes at the beginning of the level to push you on a platform.
This avoids floating down the whole river and saves more than a minute.
With a tool-assisted replay, the level can be beaten in 0:39.
width x height (in pixels): 1792 x 1024
Items:
1x bonus level
1x boomerang
2x double banana
1x extra lifes
1x mask
0x stones
1x time
Passing Criteria:
Collect all gems
Level 6 (TREE VILLAGE)
Next, Mowgli is in the tree village where he has to defeat the monkeys.
This level is relatively easy with its gimmick being some teleporting tree houses.
With a tool-assisted replay, the level can be beaten in 1:10.
width x height (in pixels): 2048 x 1024
Items:
1x bonus level
1x boomerang
0x double banana
0x extra lifes
0x mask
2x stones
1x time
Passing Criteria:
Collect all gems
Defeat the monkeys
Level 7 (ANCIENT RUINS)
Again a rather easy level with teleporting doors as a gimmick.
With a tool-assisted replay, the level can be beaten in 0:35.
width x height (in pixels): 2048 x 1024
Items:
1x bonus level
2x boomerang
2x double banana
1x extra lifes
1x mask
0x stones
1x time
Passing Criteria:
Collect all gems
Level 8 (FALLING RUINS)
This level is quite outstanding as jumping up the falling stones is your primary objective.
At the end of this stage, a single gem and a fight with King Louie await Mowgli.
During the boss fight, King Louie occasionally drops items with the shovel (bonus level) being one of them.
While jumping from stone to stone is relatively easy, some parts of this level require you to jump on stones without seeing them.
At this point having a map comes in handy.
With a tool-assisted replay, the level can be beaten in 1:31.
width x height (in pixels): 1056 x 1728
Items:
1x bonus level
2x boomerang
2x double banana
1x extra lifes
1x mask
0x stones
1x time
Passing Criteria:
Collect the single gem
Defeat King Louie
Level 9 (JUNGLE BY NIGHT)
This level plays in a similar setting as the first level, but now by night.
That also seems to be this level’s “gimmick”.
There isn’t really anything worth noting, except for a platform that seems to be unreachable (see “?” in the annotated version).
Finally something really interesting! What secrets might be hidden there? Maybe some easter egg? Or an alternative ending?
Since I was already reverse engineering the game, I was looking for some easy ways to get me there.
I chose to replace all normal jumps with catapult jumps and yeet me up there.
Using the code, this can be achieved by simply replacing JUMP_DEFAULT with JUMP_CATAPULT.
With catapult jumps throwing me through the level I finally arrived at the mysterious platform, and I found… a walking monkey, which drops a health package.
So, I guess this unreachable platform is just a flaw in the level’s design…
With a tool-assisted replay, the level can be beaten in 0:55.
width x height (in pixels): 2048 x 1024
Passing Criteria:
Collect all gems
Items:
1x bonus level
2x boomerang
3x double banana
1x extra lifes
2x mask
0x stones
1x time
Level 10 (THE WASTELANDS)
This is the final level in which you have to defeat Shere Khan.
Besides some fire on the ground, there’s nothing particularly special.
Just be careful with the last checkpoint as it may soft lock you.
With a tool-assisted replay, the level can be beaten in 0:44.
Passing Criteria:
Collect the single gem
Defeat Shere Khan
Items:
0x bonus level
2x boomerang
0x double banana
1x extra lifes
1x mask
2x stones
1x time
width x height (in pixels): 2048 x 1024
Level 11 (Bonus)
This is the bonus level, which can be reached by collecting a shovel in a regular level.
I labeled it “Level 11” due to game internally encoding it as the 11th level.
The point of this the level is to gear up Mowgli with all sorts of weapons, extra lifes, and continues.
However, the actual type of items is randomly determined, which is annotated by a “?” in the annotated version of the level’s map.
The level finishes when all eight items have been collected or when the time runs out.
width x height (in pixels): 768 x 640
Items:
8x random item
Level 12 (Transition)
This is the transition “level” which is used in between levels.
It’s not really a level, but the game internally encodes it as the 12th level.
You cannot move here, and there are several animations playing depending on what you collected in the previous level.
Usually you only see the left part of the level, but after finishing Level 10, the camera moves to the right and reveals the girl from the nearby village.
Nothing really special happens and after a few seconds the credits are shown.
width x height (in pixels): 320 x 160
Putting It All Together
Since I was way too invested into the game, doing a speedrun was the next logical step.
Here’s my attempt that I also submitted to www.speedrun.com.
To comply with the speedrun rules I played the Disney Classics version.
I fucked up a few times, but I still managed to get the first place 😎
The Reverse Engineering Process
In this section, I highlight the details of extracting the level maps from the game.
All code references are taken from the corresponding Github repository.
When I initially planned to extract the maps from this game, I was like: “That’s going to be easy, I just need to find the right memory location and copy the data.”
Well, turns out I was wrong, as the game uses way too many methods to cram the maps into the 128 kiB of the cartridge.
To understand how much compression you need, let us do some basic calculations.
Level 1 (JUNGLE BY DAY) has a size of 3072 x 512 pixels.
With two bits per pixel that would be 384 kiB (3072 x 512 x 2 / 8 = 384 kiB) of data.
That is around 3 times more than the size of the cartridge (128 kiB).
And that is just one of 10 levels.
So, what are the tricks here?
The first “trick” is the Game Boy’s way of tile-based rendering.
Instead of providing the data for the whole screen pixel per pixel, so pretty much like a framebuffer, you provide 8x8-sized tiles and pointers to the tiles.
The idea is to reuse tiles across the screen and save enormous amounts of memory.
So, the first step of the reverse engineering process was finding out where the data of the tiles resides in the ROM.
It took me a while, but I managed to find an array that holds pointers to the tiles for every level:
; $409a: A 4-tuple per level (vram pointer0, pointer to compressed data0, vram pointer1, pointer to compressed data1)
; The first pointer points to data for the general level setting (jungle, tree, ruins, etc.).
; The second pointer points to data for level-specific stuff (catapult, elephants, etc.).
CompressedMapBgTilesBasePtr::
dw $9000, CompressedMapBgTiles1, $96c0, CompressedMapBgTiles10 ; Level 1: JUNGLE BY DAY
dw $9000, CompressedMapBgTiles2, $96d0, CompressedMapBgTiles20 ; Level 2: THE GREAT TREE
dw $9000, CompressedMapBgTiles1, $96c0, CompressedMapBgTiles30 ; Level 3: DAWN PATROL
...
As already mentioned in the code’s comments, each level has a basic tile palette, such as a plain jungle setting, and some special level-specific tiles, such as a catapult.
Unfortunately, the data is not residing as simple tile palettes in the ROM.
Instead, the data is compressed and the game uses a decompression algorithm to get it in a usable structure.
Also other games, such as Looney Tunes: Carrot Crazy used similar means.
After reverse engineering the code and reading some stuff about compression algorithms, I eventually managed to find out that the developers used the Lz77 algorithm.
If you are interested in the implementation of the algorithm, search the source code for DecompressData.
Using the LZ77 algorithm, the 1728 bytes of tile data for the first level can be compressed to 1247 bytes.
So, a space saving of 27.8%, which is something but not that much.
After rewriting the algorithm in Python, I managed to extract the basic and special tile palettes.
For instance, the combined basic and special tiles for the first level (JUNGLE BY DAYLIGHT) look like this:
Note that for some levels some special cases arise, but this is basically the gist of it.
After obtaining the tiles, the next step is to obtain the indices, also called tile map.
These indices are simple 8-bit integer numbers indicating where each tile is put to.
At first, I thought the levels would use a simple 2D array.
But if I had calculated the size of the array, I could have seen at the beginning that this idea does not work out.
With the first level having a size of 3072 x 512 pixels, you would need (3072/8) x (512/8) = 24,576 bytes for the indices.
As the other levels have a similar size, putting 10 levels like that into a 128 kiB cartridge does not really work.
So, I had to do some more reverse engineering.
The conclusion was that the game uses tiles to create meta tiles (with 16 x 16 pixels, or 2 x 2 tiles).
And these meta tiles are again used to create bigger meta tiles (with 32 x 32 pixels, or 4 x 4 tiles).
Here are the 2x2 and 4x4 meta tiles of the first level (maybe open them in a new tab and zoom in):
As nicely described in this post, also other games seem to use a similar concept.
Using these big meta tiles, the indices of the first level are stored in a 2D array, only requiring (3072/32) x (512/32) = 1536 bytes!
Of course you need some data to construct small and big meta tiles, but reusing all kinds of tiles across levels also helps to reduce the memory footprint.
If you want to extract the maps yourself, feel free to use the python script I wrote.
Bugs And Glitches
During the reverse-engineering process as well as my speedrunning attempts, I came across curious design choices or even bugs and glitches.
Here are my findings.
Weapon Damage Glitch
Once a projectile hits an enemy, the game calculates the damage an enemy receives with the following code:
...
ld a, [WeaponActive] ; Glitch: Using the active weapon is not the shot weapon! Damage calculator is broken!
add a ; a = 2 * a
jr nz, .NonDefaultBanana
ld a, DAMAGE_BANANA ; a = 2
.NonDefaultBanana:
inc a ; a += 1
ld d, a
ld a, [DifficultyMode] ; normal = 0, practice = 1
or a
jr z, .NormalMode
sla d ; Projectiles deal 2x damage in practice mode.
...
First, the game loads the actively selected weapon, whereby the following values are used:
Banana (0), double banana (1), boomerang (2), stones (3).
Now that value is multiplied by 2. Except for the default banana which is just set to 2.
Then the value is increased by one. Finally, the damage is multiplied by 2 in case the game is played in practice mode.
Using this implementation is somewhat glitchy, because the projectile hitting an enemy is not necessarily the active weapon!
So, if you change the weapon using SELECT while a projectile is flying, the flying projectile inherits the damage of the active weapon.
For instance, if you fire a double banana and quickly switch to stones, the damage of the bananas is based on the stone damage, allowing you to deal 2x14=28 in a single shot (practice mode assumed).
Note that switching to an active weapon requires at least one projectile of that kind.
Teleport Glitch
When using portals to teleport, the player’s position seems to be changed immediately while the view of the window follows an animation.
During the animation, the player cannot move unless there is a liana directly under the targeted portal.
This liane can grabbed when pressing the down direction during the animation.
Such a scenario can be found in Level 6 (TREE VILLAGE) and allows you to already move forward while the animation is playing.
If you go far enough, Mowgli can be placed out of bounds bringing the game into some glitchy state.
Enemy Point Glitch
Hitting an enemy with a projectile grants you 50 points and subtracts the projectile’s damage from the enemy’s health.
However, when getting too far away from an enemy, the game unloads the enemy from the RAM.
During this process, the decreased health is not stored!
Hence, when entering the spawning zone of the enemy, it will respawn with full health, allowing you to hit it again and collect some points.
Conclusion
Thanks for reading this post :)
Please write me a mail if you have any corrections, additions, or simply an interesting story about the game.
This post is an extended and completely reworked version of our paper “The Optimal Quantum of Temporal Decoupling”,
which I presented at the 29th Asia and South Pacific Design Automation Conference 2024.
The preprint version of the paper can be downloaded here 🗎.
A big “thank you” goes to Ruben for doing the hard work behind this paper.
The idea of this work is to shine a greater light on Temporal Decoupling (TD) in Electronic System Level (ESL) simulations.
More specifically, we embarked on the quest to find and understand the optimal quantum.
In contrast to the paper, this post focuses more on SystemC-based examples.
Hence, some basic knowledge of SystemC is required to understand the rest of this post.
For everything else, even including temporal decoupling, we provide some gentle introduction.
This directly leads us to the first question:
2. What is Temporal Decoupling?
Temporal Decoupling (TD) is a modeling style that aims at speeding up (SystemC) simulations.
The principles behind TD can best be explained by some minimal example.
Let’s suppose we want to model a very simple SoC comprising 2 CPUs.
In terms of SystemC/C++, the system might look like this (download the cpp file here):
#include<iostream>
#include"systemc.h"structCpu:publicsc_module{SC_HAS_PROCESS(Cpu);voidthread(){while(true){// Do stuff...std::cout<<name()<<": "<<sc_time_stamp()<<std::endl;wait(1,SC_NS);}}Cpu(sc_module_namename):sc_module(name){SC_THREAD(thread);}};structSoc:publicsc_module{SC_HAS_PROCESS(Soc);Cpucpu0,cpu1;Soc(sc_module_namename):sc_module(name),cpu0("cpu0"),cpu1("cpu1"){}};intsc_main(intargc,char*argv[]){Socsoc("soc");sc_start(10,SC_NS);return0;}
As you can see, the two CPUs are repeatedly calling wait with a nanosecond delay in their thread, resulting in an effective clock speed of 1 GHz.
Usually, the “Do stuff…” part executes the current instruction of the CPU,
but for the sake of simplicity this is not modeled.
Thus, the example exhibits a typical SystemC loosely-timed (LT) style, in which each instruction executes in one cycle.
To see everything in action, execute the program above to get the following output:
soc.cpu0: 0 s
soc.cpu1: 0 s
soc.cpu0: 1 ns
soc.cpu1: 1 ns
soc.cpu0: 2 ns
soc.cpu1: 2 ns
[...]
The output also reveals that the SystemC kernel first executes the cycle of “cpu0”, while then executing the cycle of “cpu1”.
While there’s actually nothing wrong with this kind of modeling, the performance of the simulation might be somewhat disappointing.
Using this very simple example from above, I achieve at most 12 MIPS on my Intel i5-8265U (click here for a benchmark version).
For sure, it’s not the latest and greatest CPU, but 12 MIPS is nothing!
Especially, if you consider that the program doesn’t even do anything.
With other simulators, such as QEMU, I can easily crack 1000 MIPS.
I know, it’s a bold comparison, but I’ve heard people preferring QEMU-based simulations over SystemC-based simulations because “SystemC is so slow”.
And that leads us to very important question: Why is SystemC “so slow”?
Well, SystemC per se is not slow.
In the given example, it’s rather the frequent use of wait that cripples the simulation’s performance.
Because whenever wait is called, the SystemC kernel switches to the context of the other SC_THREAD.
While wait enables some kind of coroutine semantics, SystemC context switching comes at a relatively high price in terms of performance.
And this is where the idea of Temporal Decoupling (TD) begins.
Instead of doing a context switch for each cycle, we just let a CPU run for multiple cycles before switching to the other thread.
In other words: one CPU can run ahead of time, temporally decoupling it from the rest of the system.
Again, concepts are best explained by examples, so let’s look at the initial code, but now incorporating TD:
structCpu:publicsc_module{SC_HAS_PROCESS(Cpu);tlm_utils::tlm_quantumkeeperqk;voidthread(){while(true){if(qk.need_sync())qk.sync();// Do stuff..std::cout<<name()<<" current time:"<<qk.get_current_time()<<std::endl;qk.inc(sc_time(1,SC_NS));}}Cpu(sc_module_namename):sc_module(name){SC_THREAD(thread);qk.reset();}};structSoc:publicsc_module{SC_HAS_PROCESS(Soc);Cpucpu0,cpu1;Soc(sc_module_namename):sc_module(name),cpu0("cpu0"),cpu1("cpu1"){tlm_utils::tlm_quantumkeeper::set_global_quantum(sc_time(2,SC_NS));}};intsc_main(intargc,char*argv[]){Socsoc("soc");sc_start(6,SC_NS);return0;}
Here, a few new things are introduced.
First, there is:
This static function sets the so-called quantum.
The quantum is simply the maximum time a thread can run ahead of time.
So, in the given example, a quantum of 2 nanoseconds allows the thread to simulate 2 cycles before switching to another thread.
In the CPU threads, you now also find:
if(qk.need_sync())qk.sync()
This simply checks if the thread has exhausted its quantum, and if so, syncs up with the rest of the system.
To advance the time, you don’t call wait anymore but qk.inc(sc_time(1, SC_NS)).
Ultimately, the TD simulation generates the following output:
soc.cpu1 current time:0 s
soc.cpu1 current time:1 ns
soc.cpu0 current time:0 s
soc.cpu0 current time:1 ns
soc.cpu1 current time:2 ns
soc.cpu1 current time:3 ns
soc.cpu0 current time:2 ns
soc.cpu0 current time:3 ns
...
As you can see, we now managed to cut the number of context switches in half with a quantum of 2 ns.
Using even higher quanta like 100 ns, the simulation speed could be increased to 120 MIPS on my computer! That means, the SystemC simulation is now 10x faster than without TD!
This observation is in line with the SystemC language reference manual [1],
which also describes a potential speedup of up to 10x when using TD.
Ez pz, problem solved… you may think.
Well, as so often in life, there’s no free lunch, and unfortunately, this also applies to TD.
Since some threads might advance into the future, we are changing the semantics of the simulation.
This opens the door to a whole new universe of things that may go wrong and impact the functionality/accuracy of simulations.
So, finding an “optimal” quantum that yields the best compromise between performance and accuracy is one of the key challenges when using TD.
And that is where the story of this post begins!
3. The Story
As part of an industry project, my institute developed a faster version of the simulator gem5.
We managed to speed up gem5 by more than 20x by employing some kind of parallel temporal decoupling.
It’s basically the same principle as above, but instead of simulating the quanta one after another, we are doing everything in parallel.
After a few months of development, we eventually shipped the first version of the simulator to our industry partner.
Much to our surprise, they said it didn’t work.
So, we had a joint debug session and eventually figured out the reason: the quantum was set to 1 second.
That’s a completely absurd value.
It’s like ordering water in a restaurant and suddenly the waiter starts to flood the restaurant.
In order to have a working simulation, you need quanta like 1µs or 10µs, not 1s.
But I guess it was my fault, as I told them to increase the quantum if they want to have more performance.
I mean it’s not wrong, but I should also have told them that an increased quantum may impact accuracy or even functionality.
Moreover, I could have just provided some example values.
So I thought, maybe there’s some literature that could explain the relation between quantum and accuracy more in detail.
At that point, even we had little understanding and just chose our quanta by observation.
Or in other words: the simulation is fast and doesn’t crash? That’s a good quantum.
Well, every work I found provided the same fuzzy explanation and used the same empirical methods which we also employed.
To give you some examples:
J. Engblom [2]:
“Time quantum lengths of 10k to 1M cycles are needed to maximize VP performance.
Most of the time, software functionality and correctness are unaffected by TD, and the default should be to use long time quanta.”
Ryckbosch et al. [3]:
“We set the simulation window to 10ms and the simulation quantum to 100ms in all of our experiments.
We experimentally evaluated different values for the simulation window and quantum, and we found the above values to be effective.”
J. Joy [4]:
“Increasing the quantum can cause a thread to run for a longer time, thus reducing the context switching overhead.
This increases the simulation speed, but at the cost of accuracy.”
Jünger et al. [5]:
“To increase performance, the quantum should be as large as possible to reduce context switching.
However, a large quantum reduces simulation accuracy, as events may be handled too late. Therefore, deploying TD is not trivial.”
Apparently, they all draw the same image of more quantum, more speed, but less accuracy:
However, a quantized relation is missing in all of the mentioned works.
Sure, some of the works provide speedup/quantum graphs, but they rather stick to observations than explanations.
Fortunately, for me as a Phd student, these kinds of unresolved mysteries offer the perfect opportunity to write a paper.
So, in the next few subsections, I’ll try to bring some light into the darkness by using analytical models to describe speedup and accuracy.
4. Analytical Models
Analytical models are a popular approach in computer science/engineering to describe a complex systems by simple mathematical means.
Some famous examples include:
Amdahl’s law[6],
Gustaffson’s law[7],
or the Roofline model[8].
Often the goal is not to describe something 100% accurately, but to find a parsimonious yet evocative model.
Or in the words of George Box: “All models are wrong, but some are useful”.
With a similar thought in mind, the following subsections introduce analytical models for performance and accuracy prediction in
temporally-decoupled simulations.
4.1 A Speedup Model
In this subsection, a speedup model for TD simulations is introduced.
As already mentioned before, the speedup of a TD simulation is attained by reducing the number of the simulator’s context switches.
Thus, for an ideal simulation without any context switches,
the execution time ($T_{ideal}$) is simply given by the sum of the time of all simulation segments $T_i$:
Or in mathematical terms:
\begin{equation} \label{eq:6}
T_{ideal} = \sum_{i=1}^{K} T_ {i}
\end{equation}
Practically, there are context switches (CS) between the individual simulation segments leading to a prolongued execution time $T_{real}$:
This can be modelled by an abstract, relative overhead $O_c$
\begin{equation} \label{eq:7}
T_{real} = T_{ideal} \cdot (1 + O_c)
\end{equation}
This overhead is almost inversely proportional to the chosen quantum ($t_{\Delta q}$).
Because if we double the quantum, we almost halve the number of context switches.
Note it’s “almost” because of the process at the end, which doesn’t really have a context switch.
Since most real-world simulations have way more than just a handful of context switches, this last missing context switch is negligible.
We’re also assuming that the quantum is larger than the average event distance.
For example, using quanta below 1 ns for a CPU system with a 1 ns clock cycle wouldn’t result in any changes.
But again, for most real-world scenarios this assumption should hold valid.
Using an inverse relation between quantum and overhead, the resulting formula is:
Now we are left with an overhead factor $O_c’$.
This factor can be determined by curve fitting or running two reference simulations.
For the latter the formula is:
To accurately determine the factor $O_c’$, we recommend choosing low quanta, for which the context switching time is a significant fraction of the total simulation time.
This overhead factor also has meaning.
For example, a factor $O_c’ = 15 ns$ implies that at a quantum of 15 ns half of the execution time is spent in context switching.
Ultimately, the speedup can be formulated as:
\begin{equation} \label{eq:10}
S(t_{\Delta q}) = \frac{T_{ideal}}{T_{real}} = \frac{t_{\Delta q}}{t_{\Delta q} + O_c’}
\end{equation}
Note that this equation always yields values smaller than 1.
We chose this design for several reasons.
First, the goal of TD is to reduce the number of context switches, which is just a performance-degrading environmental effect.
Hence, TD doesn’t really make simulations faster, but it prevents them from being slowed down.
Second, with this representation, it is very easy to see, how close you are to the theoretical optimum.
For example, if the speedup is already at 0.99, increasing the quantum will not yield in any significant performance increases.
To already provide a visual impression of the model, I decided to run an experiment with the system from the 2. What is Temporal Decoupling? section.
In the given graph, the model’s prediction is depicted in orange, while the measurement is represented by the blue line.
Using the formula approach, an overhead factor of $O_c’ = 10.95ns$ was determined.
If you want to conduct this experiment on your own, feel free to use the benchmark
and the corresponding python script for the graph.
More extensive experiments are presented in Section 5.1 Speedup/Accuracy Experiments.
In the next subsection, the second important aspect of TD is discussed: accuracy.
4.2 An Accuracy Model
While the aspect of speedup was very clearly defined, the term “accuracy” (or “inaccuracy”) can be understood in multiple ways.
First of all, “accuracy” can be categorized into qualitative and quantitative aspects.
Qualitative inaccuracy includes all effects that can hardly be expressed as a metric and lead to changed simulation semantics.
For example, if TD leads to the crash of a program, you observed qualitative inaccuracy.
Quantitative accuracy, on the other hand, is something that can be meaningfully captured in numbers.
For example, it can be the accuracy of interrupt timings, cache hit rates, memory bandwidth, simulation time, etc.
Since some simulations offer hundreds of simulation statistics, the question arises of which one to pick.
For our model and experiments, we only chose the target simulation time as a representative measure of accuracy.
This statistic is present in all SystemC simulations and it may capture the influence of various other factors.
Ultimately, a simulation user must individually consider which particular simulation statistics are relevant.
As before, we tried to develop an analytical model to predict and understand accuracy.
Of course this model is limited to quantitative accuracy, because the point of qualitative accuracy is its non-numerical nature.
We’re also only modeling target simulation time for the aforementioned reasons.
So, the first step in the model design was to think about, which situation in TD could lead to a changed target simulation time,
Well, there are actually a few situations with different outcomes, but we thought that the most prevalent one is process communication.
In practice this covers cases like two target CPUs communicating over shared memory.
Let’s stick to this example an take a look at the following visulization:
In the given example, Process 2 wants to send a message to Process 1.
For the bidirectional case, Process 2 also expects a response from Process 1.
The numbers in the white circles indicate the order in which the processes were executed as this
leads to different outcomes.
The example also assumes that Process 2 starts with the communication in the middle of its quantum.
Let’s dissect the individual cases one by one to get a better understanding.
For unidirectional communication, there are 2 subcases:
Process 2 gets executed first, leading to Process 1 receiving the message $t_{\Delta q}/2$ earlier
compared to a non-TD simulation.
In the vice versa case, the message is received later by $t_{\Delta q}/2$.
If both cases are assumed to be equally likely, there should be no change in target simulation on average.
One may argue about the different semantical impacts of receiving data later or earlier, but let’s not overcomplicate things and head to the next case.
For bidirectional communication, there are 3 different subcases:
Process 2 first, then Process 1 leads to a delay of $t_{\Delta q}/2$.
Process 1 first, Process 2 second and third, Process 1 fourth, leads to a delay of $3t_{\Delta q}/2$.
Process 1 first, Process 2 second, Process 3 third, Process 4 fourth, leads to a delay of $t_{\Delta q}/2$.
As you can see, all cases lead to a prolongued communication, which ultimately may lead to a prolongued
target simulation time if the communication was on the program’s critical path,
We can also see, that that this extended time depends linearly on the quantum.
So far the model assumed a communication in the middle of a quantum, which may be a little bit too simple.
To make it more accurate we modeled communications as randomly occurring events, leading us to the Poisson distribution.
The average incured prolonguation time per quantum (Case 1 and Case 3) can then be calculated as follows:
\begin{equation} \label{eq10}
\begin{split}
t_d & = t_{\Delta q} - E(X | X \leq t_{\Delta q}) P(X < t_{\Delta q}) - t_{\Delta q} P(X > t_{\Delta q}) \\\
& = t_{\Delta q} - \int_{0}^{t_{\Delta q}} rt e^{-r t} \,dt - \int_{t_{\Delta q}}^{\infty} rt_{\Delta q} e^{-r t} \,dt \\\
%& = t_{\Delta q} - (r t_{\Delta q} e^{-r t_{\Delta q}}) + rt_{\Delta q} e^{-t_{\Delta q} t} \,dt \\\
& = t_{\Delta q} - \frac{1 - e^{-r t_{\Delta q}}}{r} \\\
& = t_{\Delta q} - (1 - e^{-r t_{\Delta q}})/r
\end{split}
\end{equation}
This results in the relative timing inaccuracy of:
\begin{equation} \label{eq11}
I = \frac{t_{\Delta q}}{t_{\Delta q} - t_d} - 1 = \frac{r \cdot t_{\Delta q}}{1 - e^{-r t_{\Delta q}}} - 1 \approx r \cdot t_{\Delta q}
\end{equation}
With $r$ being the rate of cross-scheduled events per time unit.
The result is a hockey stick curve, which can be approximated by a simple linear curve (note that Case 2 yields a similar result).
This linear curve is in stark contrast to the sigmoidal speedup model.
While the attainable speedup eventually saturates, the inaccuracy continues to increase indefinitely.
This underpins why the choice of the optimal quantum is so essential.
Without specifying the linear factor in particular, the inaccuracy equation can also be written as:
\begin{equation} \label{eq12}
I = \alpha \cdot t_{\Delta q}
\end{equation}
The factor $\alpha$ can be determined by two reference simulations or curve fitting.
5. Practical Assesment
To see whether the model can stand the test of practice, running some simulations is a neccessity.
All following simulations were executed on an AMD Ryzen 3990x (64 physical cores/128 logical cores) host system.
5.1 Speedup/Accuracy Experiments
This is currently under construction.
5.2 Qualitative Accuracy
Now to one of my favorite subsection: qualitative accurracy.
As already mentioned, this concerns all effects, which change the semantics of the simulation and can hardly be captured in numbers.
That means, without TD a simulation did A and with TD it suddenly does B.
To start with a tangible example, take a look at the following Linux boot timestamps that we obtained from default gem5 and our proprietary version with TD:
In the TD simulation, the timestamps suddenly jump to extremely high numbers, which are also occasionally jumping back in time.
Obviously, something went wrong here, with TD probably being the culprit. But what exactly happened?
After spending way too much time debugging, we ultimately found the problem
in gem5’s implementation of the ARM virtual count CNTVCT_EL0 register.
This register holds an increasing count value, which is later used by Linux to derive the timestamps.
When fetching the register, the current value is calculated by the time difference between the current and the last access.
However, in TD simulations some simulation threads can run ahead of time.
That means the last access may have a higher timestamp, resulting in a negative delta.
Since gem5 stores this delta in an unsigned integer, exploding values are the consequence.
Or to summarize this in a slide from my ASP-DAC presentation:
The solution for this problem is quite simple: restrict deltas to be greater than zero.
After that, we were finally able to boot Linux using temporally-decoupled gem5.
Interestingly, J. Engblom [12] observed the same issue completely independent of ours.
He also proposes a restriction to deltas greater than or equal to zero as a solution.
The second type of observed error arises from delayed communication between simulation objects.
As previously explained, events or messages from one process to another may only become apparent at the beginning of a quantum.
This leads to a communication latency that grows quasi-proportionally with the quantum.
This communication latency could also be oberserved when executing a multi-threaded NPB benchmark with AVP64 [9],
where the synchronization of threads was delayed by TD.
Well, in theory this delay was avoidable, because thread synchronization is usually achieved by putting a waiting CPU into a low-power state.
For ARM this could be a WFI instruction.
Whenever the simulation encounters such an instruction, it could terminate the quantum early to increase performance and accuracy.
Unfortunately, due to a bug in AVP64, the WFI instruction was executed as NOP.
Note that such a behavior is actually allowed according to the ARM reference manual manual, which is why WFI instructions are usually guarded by spin loop executing NOPs.
For large quanta, this leads to an interesting effect: The total number of instructions executed increases, causing the speedup measured in host execution time to decrease.
However, the speedup of the simulator measured in MIPS stagnates or even increases since NOPs are easy to simulate.
As shown in the following figures, first effects are already visible at $t_{\Delta q}>1ms$:
At $t_{\Delta q}>100ms$, more than half of the time is spent in spin loops.
To conclude, if someone is selling a simulator that can achieve a lot of MIPS, it may actually be executing NOPs.
In addition to the effects on simulation performance, throughput or functionality of peripherals can also be affected by delayed communication.
As an example, we executed the iperf3 [13] benchmark in avp64 with the VP as a server and the host system as a client.
In our configuration, the benchmark determines the maximum throughput of a TCP-based connection between a server and a client.
As shown in the following figure, the throughput rapidly decreases from 2690 Mbit/s at $t_{\Delta q}=1µs$ to 77 MBit/s at $t_{\Delta q}=100µs$:
This performance drop can be explained by the implementation of the OpenCores Ethernet device ETHOC[14], which is used in avp64.
The device uses one thread each for sending and receiving Ethernet frames, and each of these threads is executed only once per quantum.
Thus, only one Ethernet frame can be received per quantum, which limits the maximum achievable throughput.
Ultimately, this can affect the data rate to such an extent that timeouts of the network driver watchdog occur.
The choice to send/receive only one packet per quantum is probably due to the fact that TD was not properly taken into account during the device implementation.
It would be more accurate to calculate the number of packets to be processed once per quantum based on the elapsed time.
Since the respective thread is still activated once per quantum, there would be no performance loss.
With this explanation, a steadily decreasing throughput would be expected, but we saw that the value stagnates from a quantum of 100µs.
The explanation for this can be found in the Linux’s NAPI which is responsible for interrupt handling of network devices.
When the system receives an Ethernet frame, an interrupt is generated, which leads to the execution of an Interrupt Service Routine (ISR) as in most systems.
However, since network connections can transfer considerable amounts of data, the resulting interrupts can have a significant impact on the performance of the system.
Therefore, after receiving an interrupt, NAPI masks the corresponding interrupt and switches to a poll mode for a certain time, waiting for more packets to accumulate.
Only after a certain time has elapsed, it switches back to interrupt mode and a WFI instruction is executed.
If implemented correctly, the execution of a WFI instruction leads to an early termination of the quantum, allowing the reception of the next of a next Ethernet frame.
6. Conclusion
More quantum, more speed, less accuracy
Diminshing performance returns
Inaccuracy grows linearly
Temporal decoupliing may break your simulation
Many ways
Temporal decoupling aware design
gem5 timer fix
Ethernet adapter fix
7. Related Work
“Related Work” section at the end as the motivation of this paper was a lack of related work.
Anyway, here’s a list of works/website, which I consider related our paper:
Optimizing Temporal Decoupling using Event Relevance, Jünger et al., 2021, [15]
Temporal decoupling with error-bounded predictive quantum control, Glaser et al., 2015 [16]
Speculative Temporal Decoupling Using fork(), Jung et al., 2019, [17]
Efficient Parallel Transaction Level Simulation by Exploiting Temporal Decoupling, Khaligh et al., 2009 [18]
Analytical models and computer simulation
Cost/Performance of a Parallel Computer Simulator, Falsafi et al., 1994, [19]
A Comparison of Two Approaches to Parallel Simulation of Multiprocessors, Over et al., 2007, [20]
8. References
[1]“IEEE Standard for Standard SystemC Language Reference Manual,” IEEE Std 1666-2011 (Revision of IEEE Std 1666-2005), 2012, doi: 10.1109/IEEESTD.2012.6134619.
[3]F. Ryckbosch, S. Polfliet, and L. Eeckhout, “VSim: Simulating Multi-Server Setups at near Native Hardware Speed,” ACM Trans. Archit. Code Optim., Jan. 2012.
[4]J. Joy, “Evaluating Temporal Decoupling in a Virtual Platform.” 2020 [Online]. Available at: https://www.diva-portal.org/smash/get/diva2:1530379/FULLTEXT01.pdf
[5]L. Jünger, A. Belke, and R. Leupers, “Software-defined Temporal Decoupling in Virtual Platforms,” in 2021 IEEE 34th International System-on-Chip Conference (SOCC), 2021, pp. 40–45, doi: 10.1109/SOCC52499.2021.9739242.
[6]G. M. Amdahl, “Validity of the Single Processor Approach to Achieving Large Scale Computing Capabilities,” in Proceedings of the April 18-20, 1967, Spring Joint Computer Conference, 1967.
[8]S. Williams, A. Waterman, and D. Patterson, “Roofline: An Insightful Visual Performance Model for Multicore Architectures,” Commun. ACM, vol. 52, no. 4, Apr. 2009.
[9]“ARMv8 Virtual Platform (AVP64).” [Online]. Available at: https://github.com/aut0/avp64
[10]L. Jünger, J. H. Weinstock, and R. Leupers, “SIM-V: Fast, Parallel RISC-V Simulation for Rapid Software Verification,” DVCON Europe, 2022.
[11]F. Bellard, “QEMU, a Fast and Portable Dynamic Translator.,” 2005, pp. 41–46.
[12]J. Engblom, “Some Notes on Temporal Decoupling.” 2022 [Online]. Available at: https://jakob.engbloms.se/archives/3467
[13]“iperf3 benchmark.” [Online]. Available at: https://software.es.net/iperf/
[14]“OpenCores Ethernet MAC 10/100 Mbps.” [Online]. Available at: https://opencores.org/projects/ethmac
[15]L. Jünger, C. Bianco, K. Niederholtmeyer, D. Petras, and R. Leupers, “Optimizing Temporal Decoupling using Event Relevance,” in ASP-DAC, 2021.
[16]G. Glaser, G. Nitsche, and E. Hennig, “Temporal decoupling with error-bounded predictive quantum control,” in FDL, 2015.
[17]M. Jung, F. Schnicke, M. Damm, T. Kuhn, and N. Wehn, “Speculative Temporal Decoupling Using fork(),” in DATE, 2019, doi: 10.23919/DATE.2019.8714823.
[18]R. Salimi Khaligh and M. Radetzki, “Efficient Parallel Transaction Level Simulation by Exploiting Temporal Decoupling,” in Analysis, Architectures and Modelling of Embedded Systems, Berlin, Heidelberg, 2009, pp. 149–158.
[19]B. Falsafi and D. A. Wood, “Cost/Performance of a Parallel Computer Simulator,” in Proceedings of the Eighth Workshop on Parallel and Distributed Simulation, 1994.
[20]A. Over, B. Clarke, and P. Strazdins, “A Comparison of Two Approaches to Parallel Simulation of Multiprocessors,” Performance Analysis of Systems and Software, IEEE International Symmposium on, vol. 0, pp. 12–22, Apr. 2007, doi: 10.1109/ISPASS.2007.363732.
This post is an extended and completely reworked version of our paper “Efficient RISC-V-on-x64 Floating Point Simulation”.
A preprint version of the original paper can be donwloaded here.
In order to guide expectations right from the start, I would like to answer three essential questions first.
What is this post about and is it worth reading?
This post is about floating point (FP) arithmetic in simulators/emulators.
So, if you ever wondered how simulators/emulators like QEMU or gem5 handle floating point arithmetic,
the following might be of interest for you.
Although the title says RISC-V,
the methods presented here are applicable to most other Instruction Set Architectures (ISAs) as well.
In fact, I also present a little section about Apple’s Rosetta 2 (x64-on-ARM) and the Wii/Gamecube emulator Dolphin (PowerPC-on-x64, PowerPC-on-ARM).
Should I read the paper or this blog post?
Read this post for the reasons described in the next answer.
Why did I spend my free time rewriting something I already spent weeks on?
Blog posts are better than papers because:
I don’t have to appeal to reviewers
No page limit
Additional material (data, videos, code, etc.)
How to cite?
Please prefer to cite original paper:
@INPROCEEDINGS{zurstrassen2023,author={Zurstraßen, Niko and Bosbach, Nils and Joseph, Jan Moritz and Jünger, Lukas and Weinstock, Jan Henrik and Leupers, Rainer},booktitle={2023 IEEE 41st International Conference on Computer Design (ICCD)},title={Efficient RISC-V-on-x64 Floating Point Simulation},year={2023},volume={},number={},pages={1-6},doi={10.1109/ICCD58817.2023.00090}}
2. The Story
In 2022, a colleague of mine and his friend took the courage and founded a startup.
Their flagship product is a RISC-V simulator called SIM-V[1],
which can be used to simulate RISC-V systems on x64 (or other) machines.
One of the key selling points is the almost native performance.
The simulated system is so fast, that you can interact with it like a real system.
So, how does one make a simulator go 🚀🚀🚀?
I am certainly not giving away any secrets when I reveal that the underlying technology is
Dynamic Binary Translation (DBT).
So basically the same method that is used by QEMU.
With DBT, binary instructions of the target system (RISC-V in our case) are translated into instructions of the host system (i.e. x64) at runtime and executed.
If possible, instructions are translated 1-to-1 (or at least 1-to-only-a-few), which also explains the native speed.
For example, one could simply translate a RISC-V 32-bit floating point (FP) addition fadd.s to an x64 FP addition addss.
Semantically, these two instructions seem to be identical, at least at first sight.
My colleagues thought so too and implemented it this way in their first version of SIM-V.
In practice, this method actually works quite well.
You can boot Linux systems with it, and execute many applications without encountering problems.
One of the few applications that doesn’t work with this method is the RISC-V Architectural Test Framework (RISCOF).
Unfortunately, that’s a real showstopper, since passing these tests is required to license the RISC-V trademark.
Or to quote RISCOF’s documentation:
Passing the tests and having the results approved by RISC-V International is a prerequisite to licensing the RISC-V trademarks in connection with the design.
So, passing these tests was top priority and my colleagues asked me to do an investigation.
After taking a closer look at the failing tests, I could pinpoint the following 6 reasons why they failed:
Different NaN encodings
Different instruction semantics
x64’s missing RMM rounding mode
NaN boxing
Floating Point exception flags
NaN Propagation
In the following, I will explain each of these points in greater detail.
Subsequently, I show how other simulators and how I solve these issues.
But first, I’ll explain some basics about FP arithmetic, IEEE 754, and how it is implemented in RISC-V and x64.
Feel free to skip the next section if you are already familiar with these topics.
3. Floating Point Basics
3.1 The Math
Floating point (FP) numbers are the most common way to approximate real numbers in computing.
You find them in most programming languages with names such as float, double, f32 or f64.
Due to the many ways FP arithmetic can be implemented, adhering to standards avoids a lot of problems.
This is why most software and hardware follows the IEEE 754 standard.
But also standards might be erroneous or incomplete, which is why there are now 3 versions:
They differ mostly in some details, which will be discussed later.
The most important number formats defined by IEEE 754 are binary32 and binary64.
If you program C/C++, you already know them as float and double.
In Rust they are called f32 and f64.
A FP number comprises a sign, a significand, an exponent, and a bias
with the following bit representation:
Note that the bias is implicit and fixed.
It is used to reach negative numbers in the exponent without using two’s complement.
Ultimately, the numerical value of an FP number is given by:
\begin{equation}
f = (-1)^{sign} \cdot (1.s_{p-1}s_{p-2}…s_1)_2 \cdot 2^{exponent-bias}
\end{equation}
In the formula $s_i$ refers to the bit at position $i$ in the significand.
However, there are quite a few corner cases to represent some special values.
The first case is subnormal numbers.
Whenever $exponent$ is 0, the implicit leading 1 turns into a 0.
So we get:
\begin{equation}
f = (-1)^{sign} \cdot (0.s_{p-1}s_{p-2}…s_1)_2 \cdot 2^{-bias}
\end{equation}
Having these special cases gives us some cool mathematical properties, like additions and subtractions that never underflow.
However, in many other regards like hardware complexity, some mathematical proofs, or timing side channels, it can be a pain.
Another special value is infinity. If all bits in the exponent are set and the significand is 0, the value is interpreted as $\pm \infty$.
The last special value is NaN (Not a Number),
which comes in two different flavors: quiet (qNaN) and signaling (sNaN).
qNaNs are used to represent non-meaningful results (e.g. $\infty-\infty$), while sNaNs are intended to be used for uninitialized variables/memory.
The bit pattern of a NaNs is an exponent with all bits set and a significand that is not 0.
How the encoding of qNaN and sNaN differ is explained in Section “4.1 Different NaN Encoding”.
While Equation 1 is often used to introduce and understand the concept of IEEE FP numbers,
the $p-1$ significand bits with an implicit leading 1 complicate mathematical proofs.
A representation more suited for mathematical adventures is:
\begin{equation}
\label{eq:float1}
f = M \cdot 2^{e - p + 1}, \quad e=exponent-bias
\end{equation}
With this representation, the significand is shifted so far, that it becomes an integer value.
Due to the finite number of bits in binary32 and binary64, the precision $p$, the significand $M$, and the exponent $e$ are constrained by the values given
in the following table:
data type
exponent range
precision bits
significand range
binary32
$ e_{f,min}=-126 \leq e_f \leq 127 = e_{f,max}$
$p_f=24$
$\left\lvert M_f \right\rvert \leq 2^{24}-1$
binary64
$ e_{d,min}=-1022 \leq e_d \leq 1023 = e_{d,max}$
$p_d=53$
$\left\lvert M_d \right\rvert \leq 2^{53}-1$
Note that the $p$ precision bits include the implicit leading 1. For example, a binary32 value has a precision of
24 bits of which 23 bits are explicitly stored.
Hence, the representation is only suitable for normal numbers!
Or in other words: don’t use this model to represent subnormal numbers!
Another really painful aspect of FP numbers is rounding errors.
Whenever mathematical operations, such as additions or multiplications, are performed on FP numbers, rounding
errors may occur.
In literature and this post, rounding is symbolized by the $\circ$ operator.
While rounding errors are hard to avoid, most FP hardware allows to control the sign of the error by means of rounding modes.
With these modes, you can control whether the final result is rounded down, up, to the nearest number, or however you define it.
The most recent IEEE 754 standard defines 5 rounding modes:
roundTiesToEven (mandatory)
roundTiesToAway (introduced in 2008, not mandatory)
roundTowardPositive (mandatory)
roundTowardNegative (mandatory)
roundTowardZero (mandatory)
To indicate which rounding mode is used in mathematical representations, a little acronym is added to the circle operator.
For example, $\circ_{RNE32}(a+b)$ corresponds to a 32-bit addition under Round Nearest, Ties to Even (RNE) rounding mode.
I’m using the acronyms from the RISC-V spec [5].
In the following, if no rounding mode is given, RNE shall be assumed.
To assess the numerical impact of these errors, one can use the standard error model of FP arithmetic[6].
According to the model, the error of many arithmetic operations (+, −, /, ·, √), including underflows,
can be represented as:
Whereby $\eta$ and $\epsilon$ are used to distinguish between subnormal and normal numbers:
Normal number: $\eta=0$
Subnormal number: $\epsilon=0$
The relative error $\epsilon$ is bounded by the so-called unit roundoff error $\textbf{u}$.
Note that this formula only works for the round-to-nearest rounding.
To account for other rounding modes as well, you can use a roundoff error of $2\textbf{u}$.
This is also referred to as the machine epsilon.
3.2 RISC-V Floating Point
In this subsection, I’ll explain how FP arithmetic works on RISC-V systems.
All information presented here is based on the RISC-V ISA manual [5].
In general, RISC-V is organized in so-called extensions.
Each extensions defines a certain set of instructions and other characteristics, which can be assembled to larger systems in a modular way.
This includes FP arithmetic, which is used in the extensions F, D, Q, Zfa, Zfh, Zfhmin, Zfinx, Zhinx, and Zhinxmin.
Moreover, there is a vector extension V, which also uses FP arithmetic.
Vanilla 32-bit and 64-bit FP arithmetic is provided by the extensions F and D respectively.
All FP extensions mostly adhere to the latest IEEE 754 2019 standard [4].
Accordingly, there are 5 FP exceptions and 5 rounding modes.
Reading FP exceptions and setting rounding modes is achieved by reading/writing the fcsr register
(see Figure below).
Opposed to many other ISAs, RISC-V doesn’t trigger hardware traps when encountering FP exceptions.
Hence, you cannot catch, for example, a resulting underflow without constantly checking the fcsr register.
Another interesting characteristic of RISC-V is the instruction-embedded rounding mode.
That means, it possible to specify an operation’s rounding mode directly in the instruction’s encoding.
However, if the instruction’s rounding mode encodes to “dynamic”, a global rounding mode from fcsr is used instead.
A special peculiarity, that is not part of the IEEE standard, is RISC-V’s hardware-assisted NaN boxing.
With NaN boxing, the upper bits of an M-bit FP register are saturated if an N-bit value is written to it with $M>N$.
Also, values smaller than FLEN (FP register width) are only considered valid if the upper bits in the register are set.
For example, if a 32-bit FP value resides in a 64-bit register, it is only considered valid if the top 32 bits are set to 1.
This means, instructions working solely on 32-bit FP values must check the upper bits when reading the operands and set them when writing back the result.
Since the whole 64-bit value encodes to a negative qNaN, there is no risk of creating valid values by accident.
One issue where the IEEE standard leaves/left too much freedom in my oppinion are canonical qNaNs.
A canonical qNaN is the specific bit pattern returned by the hardware if it executed an invalid operation (e.g. 0/0).
For example, a 32-bit zero-through-zero division will result in 0x7fc00000 for 32-bit FP registers.
The same 32-bit division for 64-bit FP registers results in a NaN-boxed value of 0xffffffff7fc00000.
But more on that later in Subsection Different Canonical qNaN Encodings.
3.3 x64 Floating Point
Similar to RISC-V, FP arithmetic on x64 is also defined by extensions.
Yet, the story for this ISA is a little bit more convoluted.
The first FP ISA for x64 was introduced in 1980 by the x87 extension.
This extension was succeeded by SSE in 1999, which not only provided scalar FP arithmetic but also vector instructions.
Even though SSE mostly superseded x87, today’s x64 CPUs still support the x87 extension for legacy reasons I guess.
Modern compilers like gcc primarly generate SSE instructions when it comes to scalar FP arithmetic.
There are only a few corner cases like long double, for which gcc will still generate x87 code.
In 2011, Intel and AMD released the first processors including the AVX extension, which had new SIMD and scalar instructions.
This was followed by AVX-512 in 2016, which adds scalar FP instructions using an instruction-encoded rounding mode.
Yet AVX-512 isn’t even supported by many modern CPUs and in general doesn’t seem to be a very beloved child.
Or to quote Linux Torvalds: “I hope Intel’s AVX-512 ‘dies a painful death’.”.
So, after having introduced 4 different FP extensions, which one is relevant for the following?
It’s not x87 due to its obsolescence, and it’s not AVX-512 due to its unpopularity.
Consequently, we are left with SSE and AVX.
Since SSE is the default extension when using gcc, the rest of this section describes how FP works for SSE.
Since SSE was introduced in 1999, it mostly adheres to the most recent IEEE standard at that time, which was IEEE 754-1985 [2].
That means, opposed to RISC-V, x64 misses the RMM rounding mode, which was introduced in later standards (see Figure above).
The first standard already defined the five FP exceptions (invalid, underflow, overflow, inexact, divide-by-zero).
So, x64 is equal to RISC-V in that regard.
Surprisingly, mapping the FP exceptions from host to target turned out to be one of the most difficult challenges, as shown in the subsequent section.
As already teased above, x64 mostly adheres to the IEEE 754 standard.
Well, SSE didn’t really change any specification, but they added additional features.
For instance, x64 also defines a denormal flag for the detection of subnormal results. Also, x64 allows to treat subnormal numbers as 0 using the FTZ and DAZ flags.
Because depending on the microarchitecture, the processing of subnormal numbers can reduce your FPU’s performance by 10-100x [7]!
But if you just map subnormal numbers to 0, you may lose some precision, but there’s no risk of a severe performance drop.
This flush-to-zero mode was designed for 3D applications where performance is a greater concern than accuracy
[8].
Besides defining a lot FP stuff, the IEEE 754 still leaves some room for implementation-defined behavior.
One such thing are trapping FP exceptions, which may or may not be present on a system.
In that regard the x64 ISA takes a hybrid approach allowing to specify which FP exceptions cause a trap.
The corresponding masking bits are selected in the FMASK field, as depicted in the Figure above.
Another implementation-defined difference between RISC-V and x64 is the canonical NaN encoding.
On x64 systems, the canonical qNaN uses a negative sign, while RISC-V uses a positive sign.
That means, a 32-bit qNaN as a result of an invalid operation would be encoded as 0xffc00000.
4 The Problems
As already mentioned in Section 2, we are facing 6 different problems when executing RISC-V instructions on x64 hosts.
In the following, I provide a more detailed explanation for each of them.
4.1 Different Canonical qNaN Encodings
For some operands, certain FP instructions cannot provide a meaningful result.
For example, when multiplying ∞ and 0, or when adding +∞ and -∞.
To indicate the occurrence of an invalid operation, a specific pattern bit pattern has to be returned.
This pattern is referred to as a qNaN (quiet Not A Number).
There is also an sNaN (signaling Not A Number), but this is rather irrelevant in our case.
So, how does the bit pattern of a qNaN look like?
The IEEE 754 standard from 1985 defines a NaN very vaguely as a number with all exponent bits set to one,
and a non-zero significand.
The exact difference between a qNaN and an sNaN was specified in the 2008 version, with a qNaN having a leading “1” in the significand
and sNaN having a leading “0”.
So, according to the latest IEEE 754 standard, a 32-bit qNaN looks like this:
x111 1111 11xx xxxx xxxx xxxx xxxx xxxx
x = arbitrary bit
As you can see, there’s not only one qNaN, but a whole range of patterns, leaving an ISA designer with the problem
of which exact pattern to return when encountering an invalid operation.
Since IEEE 754 unfortunately does not give a recommendation here, we see various patterns in practice.
The following extended table from [9] shows the qNaN patterns of some popular ISAs.
ISA
Sign
Significand
IEEE 754 2008 compliant
SPARC
0
11111111111111111111111
✓
RISC-V $< v2.1$
0
11111111111111111111111
✓
MIPS
0
01111111111111111111111
✗
PA-RISC
0
01000000000000000000000
✗
x64
1
10000000000000000000000
✓
Alpha
1
10000000000000000000000
✓
ARM64
0
10000000000000000000000
✓
PowerPc
0
10000000000000000000000
✓
Loongson
0
10000000000000000000000
✓
RISC-V $\geq v2.1$
0
10000000000000000000000
✓
As you can see, the qNaN of RISC-V and x64 differ in their signs.
Thus, if we were to translate RISC-V FP instructions one-to-one to x64, we’d have to check for qNaNs after each instruction.
If qNaN is encountered as a result, the sign must be inverted.
In case you’d like to see the different qNaNs, execute the following code on different ISAs:
Now to one of my favorite problems, which shows in an absurd way that even IEEE standards created by experts are not impeccable.
Let’s start with a simple question: What is the maximum of an sNaN and an arbitrary number?
Or expressed directly as instructions:
I guess the results show quite well, that some instructions cannot be mapped 1-to-1.
So, why is that?
The answer is interesting, but not relevant for the understanding of the rest of the post.
Thus, feel free to skip the rest of this subsection.
Let’s start with the odd behavior of the x64 maxss instruction.
When the modern x64 FP arithmetic was introduced as part of the SSE extension in 1999, the current
IEEE 754 standard was still from 1985.
If you look into this standard and look for guidance on maximum/minimum instructions, you find exactly… nothing!
So, here is my guess how Intel’s engineers made it more or less compliant.
Instead of regarding the maximum/mininum instruction as atomic, you define it using order relations.
For example, using C++ syntax, you could define it as:
a>b?a:b;
Fortunately, we find some information about comparisons in the standard.
IEEE 754 1985 defines any comparisons with NaNs as unordered, requiring false to be returned [10].
This means, 5.f > sNaN is false, as well as sNaN > 5.f.
Also things like sNaN == sNaN evaluate to false.
So if every comparison with NaN is false, our maximum/minimum instruction defined by order relations will always return the second operand (b)
if one or more operands are NaN.
And that’s exactly what you see with x64’s maxss instruction.
A few years later, the IEEE 754 2008 standard was published, which finally included a definition of the maximum/minimum operation
(see subsection 5.3.1 General operations, maxNum and minNum).
According to this standard, maximum/mininum should return a qNaN when one of the operands is a sNaN.
If only one of the operands is a qNaN, the number shall be returned.
This definition was adopted by the RISC-V ISA for the fmax/fmin instruction and kept until version 2.2.
In comparison to maxss, this instruction is commutative, which is what a maximum/minimum operation should be in my opinion.
So apparently, the experts thought about commutativity, but a closer look reveals they forgot about associativity.
In his article The IEEE Standard 754: One for the History Books[11] the author David G. Hough confirms
that the aspect of associativity in the presence of NaNs was simply overseen.
To show you what is meant by this, consider the following operations:
If you just follow the standard, you get different results depending on the way the operations are associated.
That sounds like a possible source of trouble, so the experts rectified the definition in the IEEE 754 2019 standard.
To be more precise, they replaced maxNum and minNum with the associative operations
maximumNumber and minimumNumber.
They also introduced maximum and minimum, but these are not relevant in the context of RISC-V.
These new operations simply do not turn sNaNs into qNaNs which makes them associative and commutative.
Since RISC-V tries to adhere to IEEE 754 standard and is also not afraid to change things,
the fmax and fmin were adjusted in version 2.2.
So here we are. We just needed 34 years to figure out what the maximum/minimum of two values is.
Besides maximum and minimum, also other instructions like fused multiply-add and float to integer conversions show slightly different behavior.
Execute the following program on x64 and RISC-V to see it with your own eyes:
As already explained in the background section, x64 misses the “roundTiesToAway”, which was introduced in the IEEE 754 2008 standard.
So, whenever we want to simulate RISC-V FP instructions under a “roundTiesToAway”, the host’s FPU cannot be used.
Yet, this is a corner case, as most applications just use the default RNE rounding mode.
4.4 NaN Boxing
Now to a unique feature/clarification that was introduced in 2017 with version 2.2 of the RISC-V FP extensions [12].
Until version 2.2, there was no definition of how 32-bit FP values are encoded in 64-bit registers.
This can lead to several problems as described in [13] and [14].
After a lively discussion, the chosen solution was a NaN boxing scheme, which was used in no other ISA at that point as far as I know
(remark: in 2019 OpenRISC 1000 also adopted NaN Boxing with version 1.3).
That means, if a 32-bit FP value is stored in a 64-bit FP register, the upper 32 bits are set to 1’s.
Hence, the 32-bit FP value is basically a payload of a 64-bit negative qNaN.
This gives you some advantage in terms of debuging capabilities, but requires additional treatment for emulation.
If you want to see NaN boxing in action, execute the following code on RISC-V and x64:
#include<iostream>intmain(){constfloata=-0.f;constdoubleb=-0.;doubleout;#ifdef __x86_64
// Storing the float does not touch the upper bits.// Hence, the output is 0x8000000080000000 (-1.0609978955e-314).asmvolatile("movsd %2, %%xmm0 \n\t\
movss %1, %%xmm0 \n\t\
movsd %%xmm0, %0":"=x"(out):"x"(a),"x"(b):"xmm0");#elif __riscv
// Output should be -qNaN due to RISC-V NaN boxing.asmvolatile("fmv.d f0, %2 \n\t\
fmv.s f0, %1 \n\t\
fmv.d %0, f0":"=f"(out),"f"(a):"f"(b):"f0");#else
static_assert(false,"No architecture detected.");#endif
std::cout<<"out = "<<out<<std::endl;return0;}
4.5 NaN Propagation
A feature recommended but not mandated by IEEE 754 is NaN propagation.
The idea is to propagate inputs NaN payloads through instruction as some kind of diagnostic information.
It is part of x64 and ARM, but RISC-V doesn’t mandate it due to additional hardware costs.
To see how it looks like, execute the following code on x64 and RISC-V:
Whenever FP instructions are executed, certain exceptions may occur.
The IEEE 754 standard defines 5 exception flags which indicate irregularities during an instruction’s execution:
invalid (e.g.: $\infty-\infty = qNaN$)
underflow (e.g.: $(1.5046328E−36)^2=0$)
overflow (e.g.: $(1.5845633𝐸29)^2=\infty$)
inexact (e.g: $0.00390625+65536=65536$)
divide-by-zero: (e.g: $1/+0 = \infty$)
This was already defined in the first standard and hasn’t changed.
So, what is the problem if RISC-V and x64 are equal in this regard?
Finding a working solution isn’t the problem, but having a fast one is.
But let me begin with the naive approach, that I call FPU guards.
It involves the following steps to load and save the FP exception flags from the mxcsr register:
It’s simple, maintainable, and ISA-agnostic. So why not use it?
Because it is ridiculously slow.
The lock guard, including FP operation, just comprises a few instructions, so you’d expect a performance
in the range of 100-1000MIPS.
But what you get is merely 2-4 MIPS, even on the most modern machines.
As a computer engineer, it’s my passion to explore such mysteries, which is what I will do in the rest of this subsection.
The slow part of my code is obviously the lock guard, which is implemented by fegetenv and fesetenv from the standard library.
Consequently, analyzing the corresponding code in glibc seems to be the next logical step.
With a few minutes of research, I found the following code
(which I also deconvoluted and commented a little bit) for the fegetenv function.
As you can see, it only comprises 3 instructions.
Two of them are responsible for the x87 part (yey, legacy), while only one is needed to fetch the mxcsr register.
In a profiling run, I could see the x87 part taking about 90% of the total execution time of the function.
That’s a big share, considering that x87 is an obsolete extension for which compilers, with a few exceptions, no longer generate code.
So, I decided to remove the x87 instructions and reevaluate the performance.
Now it was faster, but still far away from my excpectations.
Since there’s only one remaining instruction, the case is clear more or less.
In the infinite realms of the internet, I found this cool website/document,
which analyzed the throughput and latency of all x64 instructions.
The following table summarizes it for the LDMXCSR and STMXCSR instructions (load and store of the MXCSR register).
µArch
Latency
Reciprocal Throughput
LDMXCSR
STMXCSR
LDMXCSR
STMXCSR
AMD Zen 2
-
-
17
16
AMD Zen 3
13
13
20
15
AMD Zen 4
13
13
21
15
Intel Coffee Lake
5
4
3
1
Intel Cannon Lake
5
4
3
1
Intel Ice Lake
6
4
3
1
As you can see in the table, executing these instructions is relatively costly (13 cycles latency for the AMD Zen microarchitecture).
Surprisingly, AMD also performs much worse than Intel.
Since I used an AMD machine for my benchmarks, better results could have been obtained with an Intel CPU.
Anyway, I ultimately wanted an approach that works well on all microarchitectures, so I decided to go for something different as shown later.
A possible approach to hide the expensive cost of LDMXCSR and STMXCSR, is to only invoke them when the simulator switches between the generated code and
the host environment. As already hinted in the FPU guard description, multiple instructions can be between LDMXCSR and STMXCSR.
I guess this allows to attain reasonable performance, but you drastically reduce the code modularity.
You also increase the cost of switching between simulator and simulated code.
So, in the end, I took a different way.
But before I present that, the next section shows how other simulators deal with all these problems.
5. How Other Simulators Work
Whenever I code something, I try to get some inspiration from other projects first.
Or as one of my colleagues said:
“Before you code something simulation-related, ask yourself: What would QEMU do?”
Wise words to live by, so the next sections dissect the FP implementations of a few simulators, such as QEMU, rv8, and gem5.
I also present all academic works that have been published in this field to this date (2023-11-11).
Don’t worry, it’s only 3 papers.
5.1 Soft Float
The open-source projects
gem5 [15],
Spike [16],
Uni Bremem RISC-V VP [17], [18],
Whisper [19],
Bochs [20], [21],
rvsim [22],
and QEMU [23] pre-v4.0.0,
all use a method called soft float to simulate FP arithmetic.
Note that QEMU changed to a different approach in version 4.0.0, but more on that later.
The idea of soft float is to use integer arithmetic and boolean operations to mimic arbitrary FP behavior.
It often comes as a C/C++ library, making it easy to integrate.
For example, all simulators listed above use the open-source library Berkley SoftFloat by J. Hauser [24],
which is based on the IEEE 754 1985 standard.
Soft float libraries that implement the more recent IEEE 754 2008 standard include
SoftFP by F. Bellard [25],
and FLIP by C.-P. Jeannerod et al. [26].
Besides generic solutions in programming languages like C, there are also architecture-optimized soft float libraries.
For example, RVfplib[27] is an optimized soft float library for RISC-V systems that do not include the F or D extension.
The availability of multiple open-source libraries and the ease of use make it the most popular FP arithmetic simulation approach.
If you are starting to develop your own simulator, I recommend to use it for the first proof of concept.
That’s also what we did at MachineWare.
Yet, the performance might be somewhat disappointing.
Using tens or hundreds of integer instructions to simulate one FP instruction can easily reduce your performance by that same factor.
Some exact slowdown factors are provided in the results section.
If you want to enjoy the full pain of coding your own soft float library,
the Handbook of Floating Point Arithmetic[28] provides you with all the necessary background information.
5.2 rv8
The open source project rv8 [29], [30] is a DBT-based, RISC-V simulator for x64 hosts.
With rv8, the RISC-V target rounding mode and exception flags are mapped 1-to-1 to the x64 host.
So, it’s basically the FPU guard approach that I explained in Subsection 4.6 Floating Point Exception Flags.
Hence, checking and setting the target exception flags is simply achieved by accessing the x64 host’s mxcsr register.
But besides the poor performance of FPU guards on certain AMD microarchitectures, mapping the rounding modes is also a problem.
Because x64 simply misses the RMM rounding mode (see 4.3 The Missing Rounding Mode)!
So, let’s take a look at rv8’s code to see how it solves this problem (rv8/src/asm/fpu.h:9):
In the function fenv_setrm(int rm) the RISC-V rounding mode is loaded into the host FPU.
As you can see, the missing rounding mode RMM of x64 is simply mapped to RNE!
This is not correct and leads to rv8 not being compliant with the official RISC-V standard.
The other problems, such as semantically different instructions or NaN boxing, are solved by rectifications in software.
Furthermore, FP instructions are not directly translated, but use an interpreter.
This interpreter falls back to standard C++ operators to implement RISC-V instructions.
For example, the following code shows the implementation of the fadd and fmax instructions.
As of version 4.0.0, QEMU’s slow soft float approach was replaced by the faster method of Guo et al. [31].
Initially Guo et al. tried to calculate the result of an FP instruction on the host FPU and determine the exception flags in software.
However, their way of calculating the inexact exception was so costly, that ultimatley no speedup compared to soft float was achieved.
Note that they could find a fast solution for additions, but more on that in Section 5.7 You et al..
After their failed initial attempt, Guo et al. noticed an obivous but important detail:
the inexact exception is “sticky” and does not need to be recalculated if it was already set.
Or in other words: If an instructions sets the inexact flag, which is very likely, it does not need to be recalculated for all following instructions.
Well, if you clear the flag you have to recalculate it, but there’s almost no software that actually does this.
So, to avoid the high costs for the inexact calculation, an FP operation is preceded by a quick check, whether the exception must be calculated at all.
An example for the square root instruction in QEMU using the method of Guo et al. is shown in the following, simplified, code from
qemu/fpu/softfloat.c:
(yes, despite not being a mere soft float implementation, the file is called “softfloat” ¯\(ツ)/¯ )
As you can see, the function float32_sqrt starts with a call to can_use_fpu.
Here QEMU checks whether the inexact flag must be calculated at all.
Moreover, the host FPU can only be used if target and host rounding mode are the same.
It is assumed that the default C rounding mode of RNE is used and not changed during execution.
Thus, a quick check of the target’s rounding mode suffices.
Since some target architectures like PowerPC also require a non-sticky inexact exception,
the check can be skipped disabled at compile time by defining the macro QEMU_NO_HARDFLOAT accordingly.
Ultimately, it’s very unlikely that we have to resort to soft float method, which is also hinted by the compiler attribute unlikely.
To also avoid setting the underflow and invalid exception, the soft float method is used if the input is negative or subnormal.
But again subnormal values as well as negative inputs for float32_sqrt are very rare.
The idea of extending Guo’s method by checking both invalid and underflow flags was proposed by Cota et al. [32].
It was also E. G. Cota who committed the code to QEMU in 2018.
If all checks passed, which is the most probable case, the function sqrtf is called, resulting in a sqrtss instruction for x64 hosts.
With the new method of Guo and Cota, the performance of FP instructions could be increased by a factor of more than $2\times$ in comparison to soft float.
However, this speedup is only attainable if an inexact exception occurs at some point and if the RNE rounding mode is used.
Tackling the latter issue, at least for additions,
Guo et al. developed a quick inexact check, which is pretty similar to the Fast2Sum algorithm by T. J. Dekker [33].
5.4 Rosetta 2
Rosetta 2 is Apple’s x64-on-ARM emulator, which was introduced in 2020 to aid the transition from x64 to ARM-based Apple Silicon
[34].
Despite translating instructions from x64 to ARM, which is not the focus of this post,
the underlying principle can be applied to any architecture as well.
In fact, I’m currently implementing a similar thing for RISC-V, but shhhh.
Since Apple does not disclose the technical details of their products, the following statements are based on internet sources.
In general, most problems of x64-to-ARM FP simulation concern non-standard behavior and cases labeled as “implementation defined”.
For example, the FTZ and DAZ flags of the x64 ISA are not part of the IEEE 754 standard.
These flags allow to individually flush the input and output of an instruction to zero.
Similarly, the ARM ISA also allows to flush numbers to zero, yet there is no way to control both input and output as on x64.
According to [35], Apple introduced an alternate FP mode to solve this problem in hardware.
By setting a certain bit in the ARM FP control register, x64 FP arithmetic can be mimicked.
While the Rosetta 2 approach allows for maximum performance, it requires full control of the ISA and silicon.
Shortly after Apple’s release of the M1 processor [36],
the first physical implementation of the alternate FP mode,
ARM officially included this mode in the ARMv8 ISA.
More specifically, it is part of ARMv8.7 architecture extension from January 2021 [37]
and technically referenced it as FEAT_AFP (fun fact: rumours say, that AFP might also be interpreted as Apple Floating Point 🤔).
Thus, in the future, the alternate FP mode could also find its way in the products of other manufacturers.
Interestingly, just recently I saw this article about Loongson’s LBT extension
for hardware-accelerated DBT.
The Loongson ISA manual and this article still lack important details, but I guess that parts of the additional hardware features
go into a similar direction as FEAT_AFP.
5.5 Dolphin
Dolphin is an open-source Wii and GameCube emulator.
Both consoles use a PowerPC CPU, which adheres to IEEE 754 and even adds some features beyond that.
Since GameCube and Wii accompanied my childhood, understanding how Dolphin handles FP was initially more like a personal matter.
But it turned out to be actually interesting, because it provides some real-world examples,
where not adhering to the architecture’s FP specs might break things.
In general, Dolphin translates most PowerPC FP instructions to your host’s instructions, ignoring all the pain points like correct NaNs or exception flags.
That allows for super fast emulation, the most important concern for gaming console emulation.
But it turns out, that a handful of games actually rely on correct FP emulation.
So, let’s take a look at two interesting cases.
The first case concerns correct qNaN generation.
As shown in Subsection Different Canonical qNaN Encodings, x86 generates negative canonical qNaNs while PowerPC generates positive qNaNs.
Apparently, the game “Dragon Ball: Revenge of King Piccolo” relies on positive qNaNs, otherwise the following happens
(video from the progress report June 2015):
As you can see, 2 of the 5 enemies land behind the field. Unfortunately, you have to defeat all of them to progress.
To solve this bug, the variable m_accurate_nans was introduced by Tillmann Karras (commit here).
It only enables accurate qNaN generation for games like “Dragon Ball: Revenge of King Piccolo”, to not unnecessarily cripple the performance of other games,
The second case is about correct FP exception handling.
Similar to x86, PowerPC allows to trap on FP exceptions.
However, this wasn’t modelled in Dolphin, because it would be costly to simulate, and also no game uses this feature.
Well, it turns out, there are two games, which actually rely on proper division-by-zero exceptions.
The whole story is told in the progress report September and October 2021,
but let me just give you a short TLDR.
The games which rely on this feature (“True Crime: New York City” and “Call of Duty: Finest Hour”), weren’t developed for GameCube but ported from a PlayStation 2 version
by a studio called Exakt Entertainment.
On Playtation 2, a division by zero would yield the largest positive floating point number, while the GameCube (and also x86) follows the IEEE standard and generates infinity.
Since a normal number and infinity behave completely different, their processing in subsequent instructions would lead to NaNs, which would then lead to the game’s crash.
As a simple solution, the studio came up with the following idea: whenever there is division, the code traps and rectifies the result in the exception handler.
While this works for real hardware, Dolphin didn’t support FP exception traps.
To fix this issue, the emulator resorts to an interpreter mode, where each floating point instruction is a function call.
Here, checking for divisions by zero and other stuff is simply handled by C++ code.
However, the really interesting things like calculating inexact flags don’t seem to be there.
In fact, the code is quite confusing and at some points the flags are just randomly set to zero for no apparent reason at all:
voidInterpreter::fmulx(Interpreter&interpreter,UGeckoInstructioninst){...ppc_state.fpscr.FI=0;// are these flags important?ppc_state.fpscr.FR=0;...}
I love these kinds of situation where I’m like: either I’m missing something completely obvious, or the code doesn’t make sense at all.
Fortunately, this pull request from 2018 helped me to regain my confidence: the code doesn’t make sense.
But as mentioned in the pull request, maybe there was a reason for it, so better don’t touch it.
5.6 Virtual Console
Let’s stick with simulators for Nintendo consoles but this time from Nintendo itself: the Virtual Console.
Among others, the Virtual Console allows you to play N64 games on your Wii or Wii U.
I couldn’t find much about its inner simulation engine, but there is a really interesting FP bug that is actually used in the Super Mario 64 A Button Challenge (beating the game without pressing the A button).
The bug in action is shown in the following video:
So why is the platform moving upwards?
The oscillating height of the platform is implemented by a code that looks like this:
So simply a sinus that is subtracted from the platform’s position.
But in the code, there’s a little “mistake”. Can you spot it?
It may not be obvious but the double value of 0.58 is probably not what the programmer intended.
Rather a single-prevision value of 0.58f would be a better fit.
Because in the double case, the result of std::sin(time) will be cast to a double, then the multiplication will be executed with double precision, and the final result is converted to float and stored in y_pos.
A lot of unnecessary casting, but nothing that should lead to serious problems.
Unless your simulator has a bug in its FP casting operations…
As thoroughly explained in the Dolphin progress report form 2018,
the Virtual Console does not use round-to-nearest for double-to-float conversions but round-to-zero.
Hence, a rounding error will accumulate over time that pushes the platform towards 0.
With rounding errors usually being very small in comparison to the calculated number, it takes multiple hours for the platform to rise any substantial distance.
5.7 libriscv
libriscv is a RISC-V userspace emulator library.
Since it’s a library, it’s marketed as being easy to integrate and configure.
With currently 489 stars on Github (2024-06-06), its popularity gets close to rv8, so I think it’s worth being covered in this post.
Note that all of the following refers to v1.3.
Opposed to other simulators, libriscv has some toggles that allow to configure the accuracy/performance of the simulation.
For instance, simulation of the fcsr is disabled by default (e.g., option(RISCV_FCSR "Enable FCSR emulation" OFF)).
Also, things like NaN boxing are disabled by default.
But since I’m interested in accurate simulations, I closer examined the accurate paths of libriscv.
One interesting thing I noticed is the modeling of the FP exception flags.
So, let’s take a look at the following code excerpt from rvf_instr.cpp with a FP addition as an example.
// Sets the RISC-V fcsr flags.staticvoidfsflags(CPU<W>&cpu,longdoubleexact,T&inexact){ifconstexpr(fcsr_emulation){auto&fcsr=cpu.registers().fcsr();fcsr.fflags=0;if(std::isnan(exact)||std::isnan(inexact)){fcsr.fflags|=16;ifconstexpr(sizeof(T)==4)*(int32_t*)&inexact=CANONICAL_NAN_F32;else*(int64_t*)&inexact=CANONICAL_NAN_F64;}else{if(exact!=inexact)fcsr.fflags|=1;}}}// "Accurate" floating point addition.FLOAT_INSTR(FADD,[](auto&cpu,rv32i_instructioninstr){constrv32f_instructionfi{instr};auto&dst=cpu.registers().getfl(fi.R4type.rd);auto&rs1=cpu.registers().getfl(fi.R4type.rs1);auto&rs2=cpu.registers().getfl(fi.R4type.rs2);if(fi.R4type.funct2==0x0){// float32dst.set_float(rs1.f32[0]+rs2.f32[0]);fsflags(cpu,(double)(rs1.f32[0])+(double)(rs2.f32[0]),dst.f32[0]);// Nope, don't do it like this!!!}elseif(fi.R4type.funct2==0x1){// float64dst.f64=rs1.f64+rs2.f64;fsflags(cpu,(longdouble)(rs1.f64)+(longdouble)(rs2.f64),dst.f64);}...}...)
To set the FP exception flags, FP instructions call the function fsflags.
One can quickly see that this function only handles the inexact and the invalid case.
In general, other exception flags like division-by-zero, underflow or overflow seem to be missing in libriscv.
Anyway, let’s take a look at a particular flag they are apparently modeling: the inexact FP exception flag.
As you can see, the function takes an exact value and an inexact value as arguments.
The latter stems from the actual executed instruction.
If exact != inexact, then the instruction was inexact, and the corresponding flag has to be set.
So, how do you calculate an exact value, for example, for a FP addition?
Well, apparently you just upcast values to the next larger datatype and perform the addition (see: Nope, don't do it like this!!! in the code).
You can be sure that this addition was exact…
No, please don’t do it this way! It’s not exact!
As shown later, this may work for multiplications, but for other arithmetic instruction you need other methods!
Especially for the square root instruction it should appear natural that calculating something like $\sqrt{2}$ exactly may require quite a few bits.
You may be able to correctly determine some inexact cases, but it’s by far not all.
If you want to see how libriscv fails to determine some cases, compile and execute the following C++ program:
On any non-broken computer/simulator, both cases should be inexact.
With libriscv, the hard case is not detected as inexact.
5.7 You et al.
As mentioned, in Section 5.3 QEMU post-v4.0.0,
Guo et al. [31] tried to implement software-based calculations for the inexact exception, but could only come up with a solution for additions/subtractions.
Their solution looked as follows:
inexact=((a+b)-a)<b
Guo et al. don’t mention it in their paper, but that is pretty much the so-called Fast2Sum algorithm that was introduced in 1971
by T. J. Dekker [33].
According to Dekker, the result of a rounded addition can be described by the sum of its exact value and a residual:
\begin{equation}
\label{eq:fast2sum-main}
\begin{gathered}
a + b - r = s = \circ(a + b) \\\
r = \circ(b - \circ(s - a)) \quad with : |a|>|b|
\end{gathered}
\end{equation}
The residual can be calculated by rounded FP instructions as follows:
\begin{equation}
\label{eq:fast2sum-residuum}
\begin{aligned}
r = \circ(b - \circ(s - a)) \quad with : |a|>|b|
\end{aligned}
\end{equation}
As mathematically proven by Dekker, the residual $r$ holds the exact rounding error of the addition of the variables $a$ and $b$.
Hence, if the residual $r$ is not 0, the FP addition was inexact.
Additionally, the value of the residual also determines the rounding direction of the preceding addition $\circ(a + b)$.
For values greater than 0, the result of the addition was rounded down; for values less than 0, the result was rounded up.
This fact wasn’t used by Guo et al. [31],
but by You et al. [38] in 2019.
Note that Guo et al. [31] and You et al. [38] share a similar co-author.
So, ultimately, a solution to emulate RUP rounding using RNE on the host might look like this
// Fast2Sum for RUPfloatc=a+b;// Result.floatx=fabs(a)>fabs(b)?a:b;floaty=fabs(a)>fabs(b)?b:a;floatr=y-(c-x);// Rounding error.if(r!=0){inexact=true;if(r>0){c=nextup(c);// Next greater FP value.overflow=is_inf(c)?true:overflow;}}
While You et al. and Guo et al. managed to develop fast inexact checks and rounding adjustments for additions/subtractions,
other arithmetic instructions remained untouched.
They developed an inexact check for FMA instructions using integer-based intermediate results,
but their measurements show no speedup compared to a soft float implementation.
So, let’s take a look at a more successful attempt in the next section.
5.8 Sarrazin et al.
The approach from Sarrazin et al. [39] isn’t really about determining the inexactness of FMA, but it comes close to it.
Interestingly, their work was published in 2016, which predates the unsuccessful attempt of You et al. [38] in 2019.
The group of Sarrazin faced the problem of emulating FMA instructions on systems without hardware FMA support.
So, they combined UpMul with the 2Sum algorithm to get the following equations:
\begin{equation}
\label{eq:ErrFma-residual}
\begin{gathered}
M = \circ_{64}(a \cdot b) \\\
S,T = 2Sum(M, \circ_{64}(c)) \\\
r = \circ_{32}(S) \\\
E = ||S-r|| \\\
with : \circ_{32}(a)=a, \quad \circ_{32}(b)=b, \quad \circ_{32}(c)=c
\end{gathered}
\end{equation}
The output of the 2Sum algorithm is identical to the Fast2Sum algorithm, which was presented in the previous subsection.
A more detailed discussion about the differences and performance implication is provided in the following section.
The residual $T$ (yes, suboptimal variable name) determines if the addition $c$ and $a \cdot b$ was inexact.
This can have an impact on the rounding if $E$ is in the middle of two 32-bit FP numbers ($E=2^{e_r - p}$).
So, if $E$ is equal to $2^{e_r - p}$, you have to check $S$ and $T$, and adapt $r$ accordingly.
As you can see, that doesn’t really indicate if the calculation was inexact or not.
Later in Section 6.5 Fast 32-bit Fused Multiply-Add,
I show how the equations can be rearranged to fulfill that purpose.
One major disadvantage of the method by Sarrazin et al. is the dependence on larger data types.
If the residual of a 32-bit FMA instruction is computed, at least 64-bit FP precision is required.
Or more precisely, the larger data type needs at least $2p$ significand bits.
Hence, this algorithm does not work for double precision values on x64 systems.
The 80-bit precision provided by x87 FPU cannot be used, as it does not have $2p$ significand bits.
6. Methods
In this section, I show which methods I used and developed to equip MachineWare’s SIM-V simulator
with an ultra-fast FP arithmetic.
As shown in the previous section, there are numerous ways to simulate FP arithmetic.
To make life easy for myself, I implemented a soft float library for the first proof concept.
With soft float, SIM-V was able to pass the RISCOF, but the performance was underwhelming.
So, for the second attempt, I implemented QEMU’s method.
This already increased the speed significantly, and profiling showed that there was only a limited room for optimization.
In more than 99.9% of all cases, the critical exception flags are already set and don’t need to be recalculated.
From the point of view of a programmer, certainly good - there is nothing more to do!
For an ongoing Phd under pressure to publish, rather suboptimal - there is nothing more to research!
Ok, but what if I focus on some of the corner cases in which QEMU’s method doesn’t perform well?
For instance, if the target doesn’t use RNE, QEMU always has to fall back to soft float.
You et al. [38] already showed how the residual of an addition could be used to account for different rounding modes.
But they didn’t propose any methods for other arithmetic instructions, such as multiplication, division, or square root.
So, in the following, I will show for all relevant arithmetic instructions, how to quickly calculate a residual that can be used
to determine inexactness and perform directed rounding.
I call this approach floppy float, because it’s somewhere between soft and hard float.
As far as I know, the methods for division and square root haven’t been described anywhere else in literature so far.
The goal of the method is to perform equally fast as QEMU for standard rounding, and outperform it for non-standard rounding.
Besides using mathematical proofs to check the validity of the approaches,
all instructions were verified using the RISC-V Architecture Test[41],
as well as hand-crafted tests to confirm corner cases.
NOTE
In the following I’m using a positive residual (e.g. $c_{exact} + r = \circ(a+b)$).
Hence, if $r>0$, the result was rounded up, and if $r<0$, the result was rounded down.
In my opinion it feels more intuitive this way.
6.1 Fast Addition/Subtraction
As explained in Section 5.7 You et al. the work of You et. al [38] uses the Fast2Sum algorithm for the calculation of the residual $r$.
This requires two arithmetic operations, but the operands must be sorted by absolute value.
Consequently, branching instructions might be needed, which can lead to performance penalties.
As an alternative without sorted operands, O. Møller [42] proposed the 2Sum algorithm in 1965.
Similar to Dekker’s Fast2Sum algorithm, the 2Sum’s motivation was to increase accuracy in floating point calculation.
But roughly 50 years later, we found a way to use it to speed up our simulations!
Opposed to the Fast2Sum algorithm, the 2Sum algorithm does not require branching instructions, but involves more arithmetic instructions:
\begin{equation}
\label{eq:2sum-main}
\begin{gathered}
c_{exact} + r = c = \circ(a+b) \\\
a’ = \circ(c-b) \quad
b’ = \circ(c-a’) \\\
\delta_a = \circ(a’ - a) \quad
\delta_b = \circ(b’ - b) \quad
r = \circ(\delta_a + \delta_b)
\end{gathered}
\end{equation}
This algorithm also exhibits some potential for instruction-level parallelism/vectorization, as the data dependency graph reveals:
In some benchmark experiments I ran, the 2Sum algorithm was ~10% faster than the Fast2Sum algorithm when working on randomized data.
If the input data is predictable, thus favorable to the branch predictor, both algorithms achieve the same performance.
Ultimately, a 32-bit FP add for RUP rounding might look like this:
// RUP casefloatc=a+b;// Result.floatad=c-b;floatbd=c-ad;floatda=ad-a;floatdb=bd-b;floatr=da+db;// Residual.if(r!=0.f){inexact=true;if(r<0.f){// We accidentally rounded down and have to rectify the result.c=nextup(c);// Next greater FP value.overflow=(c==infinity)?true:overflow;}}
I had initially chosen the 2Sum algorithm for this work, but extensive tests later revealed severe problems with overflows.
For example, for two 16-bit FP values, assume an addition of -48.f16 and 65504.f16 (largest positive finite number).
The rounded result of this addition is 65472.f16, which is inexact with a residual of 16:
\begin{equation}
\label{eq:twosum-broken-1}
\begin{gathered}
c_{exact} + r = c = \circ(a+b) \
65456 + 16 = 65472 = \circ_{16}(65504-48)
\end{gathered}
\end{equation}
In the intermediate calculations of the 2Sum algorithm, the value of $c$ leads to infinite values:
\begin{equation}
\label{eq:twosum-broken-2}
\begin{gathered}
a’ = \circ(c-b) \
\infty = \circ_{16}(65472 + 48)
\end{gathered}
\end{equation}
Unfortunately, this leads to the residual being a qNaN:
\begin{equation}
\label{eq:twosum-broken-3}
\begin{gathered}
r = \circ(\delta_a + \delta_b) \
qNaN = \circ_{16}(\infty - \infty)
\end{gathered}
\end{equation}
So, ultimately I chose the Fast2Sum instead of the 2Sum algorithm.
6.2 Fast 32-bit Multiplication
For the fast calculation and rounding of multiplications, I exploited one interesting property of IEEE FP numbers:
multiplying two 32-bit FP values as 64-bit values always yields an exact result!
Similar to addition, this allows to calculate a residual, which can be used for rounding and setting the inexact flag.
For the sake of simplicity, I will call this approach UpMul from now on.
So, let’s start with some operands $a$ and $b$ as 32-bit FP values.
In a first step, these are upcasted to 64-bit values and then multiplied.
Since the number of significands more than doubles from 32-bit FP to 64-bit FP,
the result of the multiplication can be represented exactly.
If the exact value is subtracted from the erroneous value, the residual remains:
\begin{equation}
\label{eq:upmul-main}
\begin{gathered}
c_{exact} + r = c = a \cdot b + r = \circ_{32}(a \cdot b) \\\
r = a \cdot b + r - (a \cdot b) = \circ_{64}(\circ_{32}(a \cdot b) - \circ_{64}(a \cdot b) )
\end{gathered}
\end{equation}
The mathematical proof is provided at the end of this section.
A C/C++ implementation for the RUP rounding mode can be found in the following code:
// RUP casefloatc=a*b;doubler=(double)c-(double)a*(double)b;if(r!=0.){inexact=true;if(r<0.){// We accidentally rounded down and have to rectify the result.c=nextup(c);// Next greater FP value.overflow=is_inf(c)?true:overflow;}underflow=(is_subnormal(c)||is_zero(c))?true:underflow;}
As shown in the code, an inexact calculation has occurred if $r\neq 0$.
Subsequently, the result is rectified in case the host hardware rounded it down.
This could lead to an overflow, hence the result is checked for infinity.
According to the RISC-V ISA, tininess is detected after rounding, requiring an underflow check after rectification.
Note that underflow only occurs when the result is subnormal and inexact.
So, now let’s take a look at mathematical proof of this method.
The formula can be derived by first showing that the multiplication of the 32-bit values
as 64-bit values is exact.
Using Equation \ref{eq:float1} the multiplication can be expressed as:
\begin{equation}
\label{eq:upmul3}
\begin{aligned}
a \cdot b = M_a \cdot M_b \cdot 2^{e_a + e_b - 2p_f + 2} =
c = M_c \cdot 2^{e_c - p_d + 1}
\end{aligned}
\end{equation}
As stated in Section 3.1 The Math, this model is not suitable for subnormal numbers.
So, how to deal with this case?
The trick is, we don’t need to consider it!
Casting 32-bit FP values to 64 bit can never lead to subnormal results.
And even the following multiplication cannot lead to subnormal results.
Why is that?
The smallest subnormal 32-bit FP number is $2^{e_{f,min}- p_f + 1} = 2^{-149}$.
Multiplying the smallest subnormal 32-bit FP number with itself results in $2^{2 \cdot -149} = 2^{-298}$.
These results are still far away from the 64-bit subnormal range, which begins at $2^{e_{d,min}} = 2^{-1022}$.
GG EZ!
Next, we derive the maximum ranges of $M_c$ and $e_c$:
\begin{equation}
\label{eq:upmul5}
\begin{gathered}
|M_c| = |M_a \cdot M_b| \leq (2^{p_f}-1)^2 \leq (2^{24}-1)^2 \leq 2^{48} - 1 \leq 2 ^{p_d} - 1 \leq 2 ^{53} - 1 \\\
|e_c| = |e_a + e_b - 2p_f + p_d + 1| \leq 260 \leq |e_{d,min}|
\end{gathered}
\end{equation}
Since both $M_c$ and $e_c$ fit into the range of a double-precision value, the result of the multiplication is exact.
From Equation \ref{eq:upmul5} we can also see why $2p$ significand bits are required to represent a multiplication exactly.
As the final step, the exactness of the subtraction needs to be shown.
Here I simply used Sterbenz’ Lemma[43] .
According to his Lemma, the subtraction of two very close FP numbers is always exact.
Interesting remark: this only works if the FP number format supports subnormal.
Or to express it mathematically:
\begin{equation}
\label{eq:sterbenz}
\begin{gathered}
\text{if} \quad a/2 \leq b \leq 2a \\\
\text{then} \quad \circ(b - a) = b - a
\end{gathered}
\end{equation}
Since the values of $\circ_{64}(a \cdot b)$ and $\circ_{32}(a \cdot b)$ differ by not more than $2\times$ their subtraction is exact.
6.3 Fast 32-bit Division
For the fast division, I developed a new method called UpDiv, which was not seen in any other work before.
Similar to the UpMul method from before, both operands must be 32-bit FP values, and the goal is to compute the residual $r$.
However, in this case, the exact determination of the residual of a division is overambitious,
as certain rational numbers cannot be represented with a finite number of significand bits.
Nevertheless, the exact value of the residual is not crucial for our endeavor.
Rather, we want to know whether there was a rounding error, and if it is positive or negative.
In mathematical terms, an approximation of the residual $\tilde{r}$ is sought, for which $sgn(\tilde{r})=sgn(r)$ is satisfied.
Such an approximation is obtained by:
\begin{equation}
\label{eq:updiv-main}
\begin{gathered}
a / b + r = c_{exact} + r = c = \circ_{32}(a / b) \\\
\tilde{r} = \circ_{64}(\circ_{64}(\circ_{32}(a / b) \cdot b) - a) \cdot sgn(b)
\end{gathered}
\end{equation}
And in terms of C/C++:
// RUP casefloatc=a/b;doubler=(double)c*(double)b-(double)a;r=signbit(b)?-r:r;if(r!=0.){inexact=true;if(r<0.){// We accidentally rounded down and have to rectify the result.c=nextup(c);// Next greater FP value.overflow=is_inf(c)?true:overflow;}underflow=(is_subnormal(c)||is_zero(c))?true:underflow;}
If you are interested in the mathematical proof, here it comes.
The equation can be derived by using the standard model of FP arithmetic extended for subnormals (see Equation \ref{eq:standard-error-model}).
According to the model, the error of the FP division, including underflow and overflow, can be represented as follows:
\begin{equation}
\label{eq:updiv3}
\begin{aligned}
\frac{a}{b} \cdot (1 + \epsilon_1 ) + \eta_1 = \circ_{32}(a/b) = a / b + r
\end{aligned}
\end{equation}
If the result of the division is upcasted to 64-bit and multiplied by the value of $b$, which is also upcasted to 64-bit, the result must be exact (see previous subsection).
This allows to calculate the approximation $\tilde{a}$ as follows:
\begin{equation}
\label{eq:updiv4}
\begin{aligned}
\tilde{a} = a + a \epsilon_1 + b \eta_1 = \circ_{64}(b \cdot \circ_{32}(a/b))
\end{aligned}
\end{equation}
Subtracting $a$ from $\tilde{a}$ yields Equation \ref{eq:updiv5}:
\begin{equation}
\label{eq:updiv5}
\begin{gathered}
z = \circ_{64}(\tilde{a} - a) = \circ_{64}(a - \circ_{64}(b \cdot \circ_{32}(a/b))) = (a \epsilon_1 + b \eta_1)(1 + \epsilon_2) \\\
z =
\begin{cases}
b \eta_1 (1 + \epsilon_2) & subn.\\\
a \epsilon_1 (1 + \epsilon_2) & else
\end{cases}
\end{gathered}
\end{equation}
Although this addition can be inexact, which is described by $\epsilon_2$,
the result 0 can only be obtained if the preceding division was exact ($\epsilon_1=\eta_1=0$).
Otherwise, the sign of $z$ is directly determined by $a \epsilon_1$ or $b \eta_1$.
Next, Equation \ref{eq:updiv5} is rearranged to:
\begin{equation}
\label{eq:updiv7}
\begin{aligned}
\epsilon_1 = \frac{z}{a \cdot (1 + \epsilon_2)} \quad
\eta_1 = \frac{z}{b \cdot (1 + \epsilon_2)}
\end{aligned}
\end{equation}
Inserting Equation \ref{eq:updiv7} into Equation \ref{eq:updiv3} yields for both cases the following residual:
\begin{equation}
\label{eq:updiv8}
r = \frac{z} {b \cdot (1 + \epsilon_2)} = \frac{\circ_{64}(a - \circ_{64}(b \cdot \circ_{32}(a/b)))} {b \cdot (1 + \epsilon_2)}
\end{equation}
Therefore, the residual can only be 0 if $z$ is 0 as well.
Likewise, the sign of $r$ is directly determined by $z$ and $b$.
Consequently, we conclude $sgn(\tilde{r}) = sgn(r)$.
6.4 Fast 32-bit Square Root
The calculation of a fast square root and its residual follows the same principle as the UpDiv algorithm.
Hence, I named it UpSqrt.
I exploit that multiplication is the inverse operation of square root, and that multiplication with larger data types is exact.
The residual results according to Equation \ref{eq:upsqrt-main}:
\begin{equation}
\label{eq:upsqrt-main}
\begin{gathered}
\sqrt{a} + r = b_{exact} + r = b = \circ_{32}(\sqrt{a}) \\\
\tilde{r} = \circ_{64}(\circ_{64}(\circ_{32}(\sqrt{a})^2) - a)
\end{gathered}
\end{equation}
The proof of the algorithm is equivalent to the proof of the UpDiv algorithm.
Again, an approximation $\tilde{r}$ for the residual $r$ with $sgn(r) = sgn(\tilde{r})$ is sought.
And again, the property that the multiplication is precise on the one hand is exploited again,
if a larger data type is available, and on the other hand that the multiplication can be used as an inverse function of the actual operation.
The final result is the following expression:
\begin{equation}
\label{eq:upsqrt2}
\begin{aligned}
r = \sqrt{\frac{\tilde{r}}{1+\epsilon_2}+a} - \sqrt{a}
\end{aligned}
\end{equation}
Since the sign of $r$ is only dependent on $\tilde{r}$, $sgn(r) = sgn(\tilde{r})$ holds.
Here’s the corresponding C/C++ code:
// RUP casefloatb=sqrt(a)doubler=(double)b*(double)b-(double)a;if(r!=0.){inexact=true;if(r<0.){// We accidentally rounded down and have to rectify the result.b=nextup(b);// Next greater FP value.}}
And here’s the proof. According to the standard error model of FP, the 64-bit multiplication of the 32-bit square root $a$ results in:
\begin{equation}
\circ_{64}(\circ_{32}(\sqrt{a})^2) = \circ_{32}(\sqrt{a})^2 = (a \cdot (1 + \epsilon_1))^2
\end{equation}
Note, that a square root cannot produce a subnormal result (thus no $\eta$) and that a 64-bit multiplication of 32-bit values is always exact.
The latter is the same property of FP that I already used in the previous two sections.
Next, we subtract $a$:
Inserting $\epsilon_1$ into $\sqrt{a} \cdot \epsilon_1 = r$ gives us:
\begin{equation}
\label{eq:eq:upsqrt-proof3}
\begin{aligned}
r = \sqrt{\frac{\tilde{r}}{1+\epsilon_2}+a} - \sqrt{a}
\end{aligned}
\end{equation}
And q.e.d.
6.5 Fast 32-bit Fused Multiply-Add
For fast FMA simulation, I deployed a similar method as Sarrazin et al. [39].
Yet, I repurposed it to account for inexact excpetions.
The idea is to first calculate the exact multiplication of $a$ and $b$ using a larger data type.
Subsequently, the residual of the summation of $a \cdot b$ and $c$ is calculated using the 2Sum algorithm.
But even if this summation was exact ($r_1=0$), the final result might not be representable as 32-bit FP value.
Hence, another residual $r_2$ is calculated to determine the 64-bit to 32-bit rounding error.
Note that $r_2$ is exact due to Sterbenz’ Lemma [43].
\begin{equation}
\label{eq:fast-fma-main}
\begin{gathered}
d_{exact} + r = d = \circ_{32}(a \cdot b + c) \\\
r_1 = 2Sum(\circ_{64}(a \cdot b), c) \\\
r_2 = \circ_{64}(d - \circ_{64}(\circ_{64}(a \cdot b) + c))
\end{gathered}
\end{equation}
Finally, an approximation of the rounding error $\tilde{r}$ can be calculated, as shown in Equation \ref{eq:fast-fma-residual}:
\begin{equation}
\label{eq:fast-fma-residual}
\begin{aligned}
\tilde{r} & = r_1 + r_2
\end{aligned}
\end{equation}
Although the addition of $r_1$ and $r_2$ is not exact per se, it satisfies $sgn(\tilde{r})=sgn(r)$.
This is enabled by gradual underflows, due to which the following property holds for two arbitrary 32-bit FP numbers:
$sgn(a+b) = sgn(\circ_{32}(a + b))$.
As before, here the C/C++ code for a RUP case:
// RUP casefloatd=std::fma(a,b,c);doublep=(double)a*(double)b;doubledd=p+(double)c;doubler1=two_sum<double>(p,(double)c,dd);doubler2=(double)d-dd;doubler=r1+r2;if(r!=0.){inexact=true;if(r<0.){// We accidentally rounded down and have to rectify the result.d=nextup(d);// Next greater FP value.overflow=is_inf(d)?true:overflow;}underflow=(is_subnormal(d)||is_zero(d))?true:underflow;}returnd;
6.6 Fast 64-bit Operations
The previous upcast algorithms UpMul, UpDiv, UpSqrt, and also the FMA algorithm according to Sarrazin et al.
[39],
are all based on larger data type that can perform multiplications exactly.
As mentioned earlier, these algorithms reach their limitations for 64-bit values on x64 systems.
To circumvent these limitations, the fused multiply-add (FMA) instruction of the x64 ISA can be used.
This instruction is formalized in the FMA3/FMA4 instruction set extensions and is part of all modern x64 processors.
For example, using FMA, the residual of the UpMul algorithm can be calculated as follows:
\begin{equation}
\label{eq:example-div}
\begin{aligned}
r’ & = \circ_{64}(a \cdot b - \circ_{64}(a \cdot b)) = \circ_{64}(c_{exact} - c)
\end{aligned}
\end{equation}
However, the rounding step at the end of each FMA instruction poses a problem.
Although an FMA instruction calculates all intermediate results with infinite precision, the result is eventually rounded.
In the example shown, it is possible that $r’$ is not representable with a 64-bit precision.
One could therefore wrongly assume a value of 0, although the value is actually different from 0.
Hence, $r’=r$ does not hold in all cases.
Consequently, bounds must be determined for which $r’$ is no longer representable.
Since $r’$ is the direct result of the subtraction of $c$ and $c’$, we have to determine the smallest distance between these numbers, excluding 0.
This distance is $|d| \geq 2^{e_c - 2p_d}$.
The number of double significand bits $2p_d$ follows from the exact intermediate results of the FMA instruction.
As explained previously, $2p$ significand bits are needed for the exact representation of a $p$-bit multiplication.
In order to represent $r’$ as a 64-bit FP value, $e_c - 2p_d \geq e_{d,min} - p_d + 1$ must hold.
A simple rearrangement leads to the following inequality:
\begin{equation}
\label{eq:example-div-bound}
\begin{aligned}
e_c \geq e_{d,min} + p_d + 1 = -1022 + 53 + 1 = -968
\end{aligned}
\end{equation}
If $|c|$ is less than $2^{-968}$, my method cannot be used, and the instruction has to be calculated using soft float.
However, the range below $2^{-968}$ represents less than 3% of all 64-bit FP values.
In practice, it’s even less, as most FP values are centered around 1.
To prove this statement, I ran different 78 FP benchmarks and tracked the in- and output exponents of all 64-bit arithmetic FP instructions:
As you can, on average less than 0.1% values have an exponent less than $2^{-968}$.
A C/C++ example for the 64-bit division is given in the following code:
In this section, I show the results of some clean room benchmarks.
The goal was to assess the maximum performance of each individual instruction
for soft float, floppy float (my approach), and hard float (native FP instructions).
That means inputs and outputs are never subnormal, there are no data dependencies between the instructions, standard rounding is used,
and there’s no DBT overhead.
While floppy float and hard float aren’t really sensitive to different kinds of input data (except subnormals),
the soft float is due to its control-flow-heavy calculations.
In general, the input data was designed to favor optimistic paths in soft float.
So, let’s take a look at the results:
As you can see, simply executing FP instructions one after another (hard float) achieves around 8500 MIPS for instructions that can be executed in one cycle (max, min, add, sub, etc.).
This is explained by the FP pipeline of the host processor, which was an AMD Ryzen Threadripper 3990X in my case.
Most FP instructions can use 2 of 4 FP pipes provided by the Zen 2 microarchitecture, leading to $8500 MIPS \approx 2 \cdot 4.3GHz$.
Some instructions, such as division, square root, or 64-bit multiplication, require multiple cycles, which results in lower performance.
Nevertheless, hard float is faster than soft and floppy float in all cases.
The performance of the floppy float approach is in the range of 300-600 MIPS, and is faster than soft float by up to $5 \times$ in some operations, such as square root.
For lightweight operations, such as min or max, there is no significant difference between soft- and floppy float.
7.2 My Method vs. QEMU
Since my approach is intended to accelerate FP performance in DBT simulators,
a practical performance assessment is indispensable.
For this purpose, I integrated my approach, the method by Cota et al. [32](QEMU’s method),
and Bellard’s SoftFP [25],
into MachineWare’s DBT-based RISC-V simulator SIM-V [1].
I then conducted a performance analysis using well-known FP benchmarks
such as linpack, NPB, SPEC CPU 2017, and other representative workloads.
The results can be found in the following graph:
In the graph, the speedups of the individual benchmarks are shown, whereby the soft float method was used as a reference baseline.
All benchmarks in Subplot a) were executed with the default RNE rounding, while Subplot b) represents the same benchmarks under RUP rounding.
Please not that this graph does not compare SIM-V with QEMU!
It’s only QEMU’s method implemented in SIM-V!
Since SIM-V uses multiple other techniques to speed up simulations, a comparison wouldn’t be fair.
As can be seen in the graph, QEMU’s method and my approach achieve a speedup of $3\times$ in a best case scenario (see Subplot a), NPB/ft.A and 508.namd).
Also, in most cases, the performance of my approach is equal to the performance of QEMU’s approach when RNE rounding is used.
As explained previously, my approach is only faster when underflows occur and no inexact flags are set, or when a non-default rounding mode is not used.
Since most applications already set an inexact flag after a few executed instructions, the speedup gained from an accelerated inexact calculation is marginal.
Also, underflows are seldom, as I could confirm with a separate instruction and data study.
For example, in the case of the NPB/ft.A benchmark, not a single underflow occurred in a total of 3,875,127,289 executed fmadd instructions.
To demonstrate the advantages of my methods, I ran all benchmarks again under RUP rounding which is depicted in Subplot b).
Here we can see that QEMU is slower than soft float in all cases.
This can be attributed to the fact that QEMU first checks the rounding mode before resorting to soft float.
My method, however, can rectify the result for most instructions and set the exception flags without using soft float.
Thus, speedups of 50% over QEMU are achieved for benchmarks like linpack32.
Since the speedup of my method depends on the executed instructions, we observe a heterogeneous picture of results.
Moreover, the speedups under RNE cannot be used to infer the speedups under RUP.
As described in previously, we do not have a method for 64-bit FMA instructions,
and all presented approaches require less checks when working on 32-bit data.
Hence, single precision benchmarks, such as linpack32 or machine learning applications (lenet, alexnet), achieve higher speedups in non-default rounding modes.
Applications that comprise many 64-bit FMA instructions achieve low to no speedup (see NPB/bt.A and NPB/cg.A).
8. Conclusion & Outlook
In this post, I showed how floating point arithmetic is calculated in emulators/simulators, such as QEMU, gem5, or Rosetta 2.
To the best of my knowledge, this post provides the most complete picture of this topic to date.
But if you find more literature worth citing, let me know!
Besides just providing a related work overview, I showed how the QEMU approach can be
improved to also perform well for other rounding modes.
I implemented my method in MachineWare’s SIM-V RISC-V simulator and beat QEMU’s by more than 50% in the best case.
For the vanilla RNE rounding mode, I couldn’t achieve any speedups for standard benchmarks.
This is due to exception bits being sticky and not requiring any recalculations.
I later noticed that the PowerPC has non-sticky exception flags, which requires a recalculation for every instruction.
Hence, I guess my method could significantly speed up PowerPc simulations even for standard benchmarks with RNE rounding.
One important missing piece of this work are efficient algorithms for 64-bit FMA instructions.
Unfortunately, these instructions occur relatively frequently, costing us a significant chunk of performance for some benchmarks.
I found an interesting work of Boldo et al. [40], which provides an algorithm to calculate the residual for FMA instructions.
So exactly what I need!
But I wasn’t able to get it running correctly for whatever reason…
Since their paper is basically 8 pages of mathematical proofs, I leave this as a problem for other people and future Niko.
If you have remarks, questions, or just want to say “hello”, feel free to write me a mail!
9. References
[1]L. Jünger, J. H. Weinstock, and R. Leupers, “SIM-V: Fast, Parallel RISC-V Simulation for Rapid Software Verification,” DVCON Europe 2022, 2022.
[2]“IEEE Standard for Binary Floating-Point Arithmetic,” ANSI/IEEE Std 754-1985, pp. 1–20, 1985, doi: 10.1109/IEEESTD.1985.82928.
[3]“IEEE Standard for Floating-Point Arithmetic,” IEEE Std 754-2008, pp. 1–70, 2008, doi: 10.1109/IEEESTD.2008.4610935.
[4]“IEEE Standard for Floating-Point Arithmetic,” IEEE Std 754-2019 (Revision of IEEE 754-2008), pp. 1–84, 2019, doi: 10.1109/IEEESTD.2019.8766229.
[5]R. I. S. C.-V. Foundation, The RISC-V Instruction Set Manual, vol. Volume I: User-Level ISA, Document Version 20191213. 2019 [Online]. Available at: https://riscv.org/wp-content/uploads/2019/12/riscv-spec-20191213.pdf
[6]N. J. Higham, Accuracy and Stability of Numerical Algorithms, 2nd ed. USA: Society for Industrial and Applied Mathematics, 2002.
[7]I. Dooley and L. Kale, “Quantifying the interference caused by subnormal floating-point values,” Jan. 2006.
[8]S. Thakkur and T. Huff, “Internet Streaming SIMD Extensions,” Computer, vol. 32, no. 12, pp. 26–34, 1999, doi: 10.1109/2.809248.
[9]A. Waterman, “Design of the RISC-V Instruction Set Architecture,” 2016 [Online]. Available at: https://people.eecs.berkeley.edu/ krste/papers/EECS-2016-1.pdf
[10]“Wikipedia - Comparision with NaN.” [Online]. Available at: https://en.wikipedia.org/wiki/NaN#Comparison_with_NaN
[11]D. G. Hough, “The IEEE Standard 754: One for the History Books,” Computer, vol. 52, no. 12, pp. 109–112, 2019, doi: 10.1109/MC.2019.2926614.
[12]R. I. S. C.-V. Foundation, The RISC-V Instruction Set Manual, vol. Volume I: User-Level ISA, Document Version 2.2. 2017 [Online]. Available at: https://riscv.org/wp-content/uploads/2017/05/riscv-spec-v2.2.pdf
[13]A. Bradbury, “NaN Boxing RFC.” Mar-2017 [Online]. Available at: https://gist.github.com/asb/a3a54c57281447fc7eac1eec3a0763fa
[15]N. Binkert et al., “The Gem5 Simulator,” SIGARCH Comput. Archit. News, vol. 39, no. 2, pp. 1–7, Aug. 2011, doi: 10.1145/2024716.2024718. [Online]. Available at: https://doi.org/10.1145/2024716.2024718
[16]R. I. S. C.-V. Foundation, “Spike RISC-V ISA Simulator.” [Online]. Available at: https://github.com/riscv-software-src/riscv-isa-sim
[17]V. Herdt, D. Große, P. Pieper, and R. Drechsler, “AGRA Uni Bremen RISC-VP.” [Online]. Available at: https://github.com/agra-uni-bremen/riscv-vp
[18]V. Herdt, D. Große, P. Pieper, and R. Drechsler, “RISC-V based virtual prototype: An extensible and configurable platform for the system-level,” Journal of Systems Architecture, vol. 109, p. 101756, 2020, doi: https://doi.org/10.1016/j.sysarc.2020.101756. [Online]. Available at: https://www.sciencedirect.com/science/article/pii/S1383762120300503
[19]“Whisper Github Repository.” CHIPS Alliance [Online]. Available at: https://github.com/chipsalliance/VeeR-ISS
[20]Lawton, Kevin P., “Bochs Github Repository.” [Online]. Available at: https://github.com/bochs-emu/Bochs
[21]K. P. Lawton, “Bochs: A Portable PC Emulator For Unix/X,” Linux Journal, vol. 1996, no. 29es, pp. 7–es, 1996.
[22]Stéphan Kochen, “rvsim.” [Online]. Available at: https://github.com/stephank/rvsim
[23]F. Bellard, “QEMU, a Fast and Portable Dynamic Translator,” in Proceedings of the Annual Conference on USENIX Annual Technical Conference, USA, 2005, p. 41.
[24]J. R. Hauser, “Berkley SoftFloat.” 1996 [Online]. Available at: https://github.com/ucb-bar/berkeley-softfloat-3
[25]F. Bellard, “SoftFP.” 2018 [Online]. Available at: https://bellard.org/softfp/
[26]C. Bertin et al., “A floating-point library for integer processors,” Proceedings of SPIE - The International Society for Optical Engineering, vol. 5559, Oct. 2004, doi: 10.1117/12.557168.
[27]M. Perotti, G. Tagliavini, S. Mach, L. Bertaccini, and L. Benini, “RVfplib: A Fast and Compact Open-Source Floating-Point Emulation Library for Tiny RISC-V Processors,” in Embedded Computer Systems: Architectures, Modeling, and Simulation, Cham, 2022, pp. 16–32.
[28]J.-M. Muller et al., Handbook of Floating-Point Arithmetic. 2010.
[29]M. Clark and B. Hoult, “rv8 - RISC-V simulator for x86-64.” [Online]. Available at: https://github.com/michaeljclark/rv8
[30]M. Clark and B. Hoult, “rv8: a high performance RISC-V to x86 binary translator,” CARRV, Oct. 2017, doi: 10.13140/RG.2.2.30957.69601.
[31]Y.-C. Guo, W. Yang, J.-Y. Chen, and J.-K. Lee, “Translating the ARM Neon and VFP Instructions in a Binary Translator,” Softw. Pract. Exper., vol. 46, no. 12, Dec. 2016.
[32]E. G. Cota and L. P. Carloni, “Cross-ISA Machine Instrumentation Using Fast and Scalable Dynamic Binary Translation,” in Proceedings of the 15th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments, New York, NY, USA, 2019, pp. 74–87, doi: 10.1145/3313808.3313811 [Online]. Available at: https://doi.org/10.1145/3313808.3313811
[33]T. J. Dekker, “A floating-point technique for extending the available precision,” Numerische Mathematik, vol. 18, pp. 224–242, 1971.
[34]Apple Inc., “Apple announces Mac transition to Apple silicon.” Jun-2020 [Online]. Available at: https://www.apple.com/newsroom/2020/06/apple-announces-mac-transition-to-apple-silicon/
[35]D. Johnson, “Why is Rosetta 2 fast?” [Online]. Available at: https://dougallj.wordpress.com/2022/11/09/why-is-rosetta-2-fast/
[36]Apple Inc., “Apple unleashes M1.” Nov-2020 [Online]. Available at: https://www.apple.com/newsroom/2020/11/apple-unleashes-m1/
[37]“ARM Architecture Reference Manual.” ARM [Online]. Available at: https://developer.arm.com/documentation/ddi0487/latest
[38]Y.-P. You, T.-C. Lin, and W. Yang, “Translating AArch64 Floating-Point Instruction Set to the X86-64 Platform,” in Proceedings of the 48th International Conference on Parallel Processing: Workshops, 2019.
[39]G. Sarrazin, N. Brunie, and F. Pétrot, “Virtual Prototyping of Floating Point Units,” 2016.
[40]S. Boldo and J.-M. Muller, “Exact and Approximated Error of the FMA,” IEEE Transactions on Computers, vol. 60, no. 2, pp. 157–164, 2011, doi: 10.1109/TC.2010.139.
[41]Gala, N. and Karasek, M., “RISC-V Architecture Test.” [Online]. Available at: ttps://github.com/riscv-non-isa/riscv-arch-test
[42]O. Møller, “Quasi Double-Precision in Floating Point Addition,” BIT, vol. 5, no. 1, pp. 37–50, Mar. 1965.
[43]S. P.H., “Floating Point Computation.” Prentice Hall, 1974.
]]>par-gem5: Parallelizing gem5’s Atomic Mode2023-11-11T10:15:44+01:002023-11-11T10:15:44+01:00https://chciken.com/simulation/2023/11/11/par-gem5Most important things first: download the preprint of our paper par-gem5: Parallelizing gem5’s Atomic Mode here.
What is the paper about?
The gist of it is a parallelized version of gem5’s atomic mode.
Note that this is for the atomic mode only!
If you are intersted in the timing mode, feel free to read our sequel parti-gem5: gem5’s Timing Mode Parallelised, which is available on Arxiv.
How fast is par-gem5?
For completely parallel benchmarks we managed to reach speedups of ~25x when simulating a 128-core ARM system on a 128-core x64 host system.
More realistic parallel benchmarks like NPB “only” attain speedups of up to ~12x.
Since par-gem5 creates a thread for each simulated CPU core, the maximum attainable speedup depends on several factors.
This includes: the number of available host threads, the number of simulated target CPUs, and the degree of parallelization in the executed benchmark.
Especially the latter is important.
If you are looking to speedup the execution of a single-core benchmark like Dhrystone, par-gem5 is probably not the right tool for you!
Is par-gem5 easy to use?
I would say it is fairly simple if you are already familiar with vanilla gem5.
You only have to set a CPU’s event queue and choose a reasonable quantum.
This can all be done in the python setup scripts with the following lines:
ifargs.parallel:print("gem5 going parallel")m5.ticks.fixGlobalFrequency()root.sim_quantum=m5.ticks.fromSeconds(m5.util.convert.anyToLatency("500us"))cpus=system.cpu_cluster[0].cpus# Note: child objects usually inherit the parent's event queue.
iflen(cpus)>1:first_cpu_eq=1foridx,cpuinenumerate(cpus,first_cpu_eq):cpu.eventq_index=idx
How accurate and reliable is par-gem5?
The parallelization approach of par-gem5 is in many regards similar to SystemC TLM-2.0’s so-called temporal decoupling.
That means, rather than having one global time as in vanilla gem5, each simulated CPU resides in its own time and occasionally synchronizes
with the rest of the system at certain barrier points.
The distance of the barrier points is determined by the aforementioned quantum.
For instance, if the quantum is set to 500µs, the maximum time two CPUs can diverge is 500µs.
Surprisingly, the hardware and software of most modern general purpose CPU systems is pretty resilient to a certain amount of time skew.
If you do not yeet up the quantum to values like 1 second, you can boot linux systems and run arbitrary software workloads without encountering any problems.
Nevertheless, we are changing the semantics of the simulation and this has a non-negligible impact on multiple aspects.
For instance, if CPUs are communicating with each other, certain messages may be postponed to a barrier point, which in general leads to prolonged simulation times
(the time that is provided in the gem5 statistics, not the the so-called wall clock time).
As shown in the paper, a quantum of 1µs seems to keep inaccuracies in a single-dit percentage while still achieving significant speedups in most benchmarks.
The different time domain are also a problem for some of gem5’s hardware models.
For instance, the ARM timer model casts time differences to unsigned integers, which may result in trouble if the deltas are negative.
Here’s a snippet of the unfixed timer’s impact on the Linux boot timestamps.
As you can see, at some point the timer blows up.
That was a pain to debug, but we eventually managed to find the error and fix the timer model.
After fixing some other issues, par-gem5 is now in a state, which I would consider as quite reliable.
I would not launch a space craft with, but it’s good enough for software development and design space exploration.
Will par-gem5 be open source?
Since par-gem5 is the result of an industry project, the source code is not going to be disclosed.
Any Questions?
Feel free to write me a mail (see About).
]]>Evaluation of the RISC-V Floating Point Extensions F/D2023-08-06T11:55:44+02:002023-08-06T11:55:44+02:00https://chciken.com/risc-v/2023/08/06/evaluation-riscv-fd
window.MathJax = {
tex: {
loader: {load: ['[tex]/ams']},
tex: {packages: {'[+]': ['ams']}},
tags: 'ams',
inlineMath: [['$', '$']]
}
};
This post is an extended and remastered version of our paper “Evaluation of the RISC-V Floating Point Extensions”.
Feel free to download the preprint version here.
The paper and also this post basically comprise two parts.
First, I summarize the history of RISC-V FP floating point extensions F and D.
Additionally, I highlight the RISC-V design rationale and compare it qualitatively against ARM64 and x64.
The second part is a practical evaluation of the RISC-V FP extensions F and D.
I used a modified RISC-V VP to track aspects like the number of executed instructions, distribution of in-/output data,
usage of rounding modes, etc.
Much in the spirit of RISC-V, I provide the data as open access.
Feel free to draw your own conclusion and write me a mail if I missed something.
2. Story & Motivation
In 2022 a friend and his colleague asked me to help them with the implementation of fast floating point arithmetic in their RISC-V simulator SIM-V[1].
Just recently, I wrote a post about it.
As described in the post, every ISA from ARM64 to RISC-V has its own interpretation of how floating point works.
It’s not like they differ in major things, but there are so many minor aspects, where one ISA does A while the other does B.
Ironically, most ISAs follow the IEEE 754 floating point standard, which was particularly designed to avoid fragmentation.
Anyway, at one point I wondered why there are so many differences despite having a standard.
Or regarding this from an even higher perspective: How does one design the FP part of an ISA?
Which instructions do you implement? Which data formats do you support? Why should you (not) adhere to IEEE 754?
To quench my thirst for knowledge, I embarked on a semi-successful literature journey.
The prevailing ISAs, such as x64 and ARM64, are in the hands of big companies.
Hence, they do not disclose any details about their design decisions.
Since RISC-V is an open standard that embraces open discussions,
you find way more information.
Unfortunately, this information is spread around multiple sources.
There is a RISC-V ISA dev Google group [2],
a RISC-ISA manual Github repository [3],
a RISC-V working groups mailing list [4],
a RISC-V workshop [5],
and there are scientific publications [6], [7].
One of the goals of this post is to summarize the most important points of all these sources,
with a focus on the floating point extensions F and D.
Additionally, I evaluate these extensions using a large sample of FP benchmarks.
Because often design decisions seem to be motivated by anecdotal evidence.
But if you look for literature or data, you don’t find anything at all.
So, with this post I also want to provide some data to hone future discussions.
3. History & Background
3.1 RISC-V History and Basics
To cover a wide range of applications, such as embedded systems or high performance computing,
the RISC-V ISA provides several so-called extensions.
Each of these extensions describes a set of properties, like instructions or registers, which can be assembled to larger systems in a modular way.
This includes the F/D extensions, which extend RISC-V systems with 32-bit and 64-bit FP arithmetic respectively.
The extensions for 16-bit (Zfh) and 128-bit FP arithmetic (Q) are not considered in this work due to their relatively low popularity in general programming.
Opposed to many other extensions, the F and D extensions were already introduced in the first version of the RISC-V ISA manual [8] in 2011.
This is a bit unfortunate, as there was never a public debate about the F/D extensions’ design.
Telling from the ISA manual, it looks like these were contributed by John Hauser.
Or to directly quote the manual [8]: “John Hauser contributed to the floating-point ISA definition.”
To a large extent, the extensions implement features as mandated in IEEE 754 [7]:
“RISC-V’s F extension adds single-precision floating-point support, compliant with the 2008 revision of the IEEE 754 standard
for floating-point arithmetic.”.
Following the IEEE 754 standard is not the worst idea and already defines most parts of the FP extensions.
So, in the subsequent subsection I show how RISC-V implements IEEE 754 and how it compares to other ISAs in that regard.
The properties of the F extension can be transferred 1-to-1 to D except for the bit width.
3.2 The Instructions
The heart of any ISA are its instructions.
While at the beginning of computer development, there were still significant differences between implementations,
today’s prevalent FP ISAs are similar to a large extent.
This is mainly due to IEEE 754, which specifies the FP formats and instructions to be supported by a conforming ISA.
Also RISC-V follows the IEEE 754-2008 standard [9].
Well, that’s what they say, but more on that in a few seconds.
The following table highlights the difference between all RISC-V F instructions and their correspondents in x64 and ARM64.
It also reflects the instruction’s IEEE 754-2019 status (r=recommended, m=mandated):
As can be seen in the table, the majority of RISC-V instructions are mandated by IEEE 754 and are consequently also prevalent in x64 and ARMv8.
What the table doesn’t tell you is which instructions are mandated but not implemented by RISC-V or other ISAs.
To just name a few instructions mandated by IEEE 754 but not implemented by RISC-V [10]:
The closest FP numbers (similar to std::nextafter): nextUp(s1), nextDown(s2):
A division’s remainder: remainder(s1, s2)
Hex character conversion: convertFromHexCharacter(s1),convertFromToHexCharacter(s1):
All kinds of comparisons: greater, greater equal, not greater, greater equal, not equal, not less.
And this is just the mandated stuff.
There are many more unimplemented instructions which fall into the category of “recommended”.
So, what the f is happening here? How can RISC-V (and also the other ISAs) be compliant with IEEE 754 if it doesn’t implement all mandated instructions?
Also, how did RISC-V decide on which instruction they want to implement and which not?
Since literature didn’t help me to answer these questions, I wrote a mail to the RISC-V FP contributor John Hauser.
Much to my surprise, he took the time to answer my stupid questions. Thanks for that!
Anyway, here’s an excerpt from our conversation:
Niko: I see many mandated instructions, which aren’t implemented in RISC-V. …
John: The IEEE 754 Standard mandates that certain operations be supported, but it does not mandate that each operation be implemented by a single processor machine instruction. A sequence of multiple machine instructions is a valid impelementation, and that extends even to complete software subroutines, which is how many operations such as remainder and binary-decimal conversion are implemented, not only for RISC-V but for many other processors as well.
Niko: What was the rationale for the choice of floating point instructions?
John: Actually, I had little involvement in choosing the floating-point instructions for RISC-V.However, I believe the choice was shaped largely by the use of floating-point in “typical” programs, probably starting with the SPEC benchmarks and the GCC libraries.
As you can see (and as I confirmed with the standard), an implementation of the IEEE 754 does not neccessarily have to be in hardware.
It can also be in software or in a combination of both.
But nevertheless, labeling RISC-V as compliant doesn’t really make sense.
It’s rather the software running on top of RISC-V that makes it compliant.
Also, following this argumentation every basic microcontroller could be IEEE 754 compliant if you just have the right software.
Since we can just choose our instructions as we like, the next consequent question is: Which instruction do you implement in hardware?
As John said, usage of FP instructions and library functions in benchmarks like SPEC may have shaped the RISC-V ISA.
If this theory is correct, I should see a broad utiiization of all RISC-V instructions in SPEC and probably other benchmarks.
So, why not check if this is really the case?
In section 6.1 Instruction Distribution this theory will stand the test of practice!
But first, the subsequent subsections explain some further peculiarities that distinguish the RISC-V FP ISA from other ISAs.
1) Sign Injection
The three sign injection instructions (FSGNJ, FSGNJN, FSGNJX) were contributed by J. Hauser [11]
and are unique to RISC-V [6].
Their main goal is to implement the operations copy (FMV in RISC-V), negate (FNEG in RISC-V), abs (FABS in RISC-V), and copySign, which are mandated by the IEEE 2019 standard [10].
This is achieved by transferring the value from rs1 into rd while using a sign based on the following description:
FSGNJ rd, rs1, rs2: Sign from rs2. Implements copy if rs1=rs2.
FSGNJN rd, rs1, rs2: Negative sign from rs2. Implements negate if rs1=rs2.
FSGNJX rd, rs1, rs2: XORed signs of r1 and r2. Implements abs if rs1=rs2.
On x64 systems, the operations negate and abs are implemented using AND and XOR instructions with a corresponding bitmask.
For example, using a mask to zero out the sign bit ANDPS reg, [mask].
2) Conversions and Rounding
For every possible conversion from integer to float and vice versa, RISC-V as well as ARM64 provide the required instructions as mandated by the IEEE 754 standard.
The standard also mentions 5 different rounding modes for these instructions.
Both ARM64 and RISC-V allow to directly encode this rounding mode in the instruction.
For ARM64 it’s quite interesting. There’s in theory an rmode field which dictates the rounding direction
(see this link).
However, it only has 2 bits which makes 5 rounding modes impossible.
So, “ties to even” and “ties away” share the same rounding modes and differ in other aspects of the encoding
(00 = ties to even or ties away, 01 = plus infinity, 10 = minus infinity, 11 = toward zero).
In RISC-V, the rounding mode is given by 3 reserved bits in an FP instruction’s encoding.
Hence, we have:
000: Round to Nearest, ties to Even
001: Round towards Zero
010: Round Down
011: Round Up
100: Round to Nearest, ties to Magnitude
101: Reserved for future use
110: Reserved for future use
111: Dyanmic - use rounding mode from fcsr
There’s even space for two more rounding modes in case IEEE 754 decides to bother us with new inventions.
A similar approach can be found AVX-512, where it is also possible to encode the rounding mode in the instruction.
On x64 systems, the rounding mode has to be set in the FP CSR (mxcsr).
x64 lacks instructions to convert from unsigned 64-bit integer to float and vice versa.
3) Comparisons
While RISC-V provides comparisons, such as equal (FEQ) or less than (FLT), directly by instructions,
ARM64 and x64 take a different approach.
Here, instructions such as FCMP and UCOMISS set flags in status registers, which can be used as comparisons in subsequent instructions.
4) Classification
An instruction which cannot be found in ARM64 and x64 is FCLASS.
The instruction allows to classify a FP number into several classes, as shown in the following table, and return the result using a one-hot encoding:
rd
meaning
rd
meaning
0
$-\infty$
5
+subnormal
1
-normal
6
+normal
2
-subnormal
7
$+\infty$
3
$-0$
8
sNaN
4
$+0$
9
qNaN
This allows to quickly react to the classification by ANDing the result with a bitmask.
The instruction is recommended, but not mandated by IEEE 754-1985 [12] and referred to as Class(x).
With the IEEE 754-2008 [9] it was redeclared as mandatory and renamed to class(x).
I searched through old IEEE 754 meeting minutes for quite a while, but I couldn’t find anything about the rationale for this decision.
Please write me a mail if you know more!
The classification instruction can be found in other ISAs as well,
including Intel i960 (CLASS{R/RL}) [13],
LoongArch (FCLASS.{S/S}) [14],
IA-64 (FCLASS) [15], and
MIPS64 (CLASS.{S/D}, since release 6) [16].
It is also present in Intel’s 80-bit x87 extension as FXAM [17], which is the predecessor of SSE.
Interestingly, Intel decided to remove this instruction from all subsequent extensions.
Some architectures like PowerPC [18] or OpenRISC 1000 [19] implement class in an implicit way.
With PowerPC, for example, after each FP instruction, a classification of the result is stored in a register called FPSCR_FPRF.
The purpose of the FCLASS instruction is to allow software to react to unusual outputs from other FP instructions with relatively cycle low overhead.
In [7] A. Waterman argues that library routines often branch at outputs like NaNs.
However, without a designated instruction, this check can take “many more instructions”.
To what extent cycles are saved is not mentioned.
The article also lacks information about how often class is used in practice, and which exact outputs trigger branching.
To remedy this circumstance, I decided to run some experiments on my own.
The results are presented in Section 6 Results & Discussion.
5) Maximum/Minimum
What is the maximum of a numerical value and a signaling NaN?
Right, it depends!
Depending on the used IEEE 754 standard, you might end up with different answers.
With the new IEEE 754-2019 standard, RISC-V unflinchingly changed its definition to incorporate some bug fixes.
ARM64 and x64 didn’t, so their maximum/minimum isn’t really the same as RISC-V’s.
If you want to learn more about the maximum/minimum messup, take a look at my other blog post.
3.3 The Registers
In addition to the general purpose registers, the RISC-V F extension adds 32 dedicated FP registers with a bit width of FLEN=32 (FLEN=64 for D).
During the development of RISC-V, a unified register file was initially considered,
but a separate register was ultimately chosen because of the following reasons [7]:
Some types do not align with the architecture. For example, using the D extension on an RV32 system.
Separate registers allow for recoded formats (internal representation to accelerate handling of subnormal numbers [20]).
This plays an inmportant role later in Section 6.3 Subnormal Numbers & Underflows.
There are more addressable registers (the instruction implicitly selects a set of registers).
Natural register file banking simplifying the implementation of superscalar designs.
As explained in [7], a separate register file comes with the following drawbacks:
Register pressure increases unless the number of registers is increased. Soft spilling can be used to mitigate this issue.
Context switching time might increase due to additional register saves. To mitigate this issue, RISC-V introduced dirty flags. Registers are only saved if their content changed.
Besides general purpose FP registers, the F extension also adds a CSR to configure rounding modes and indicate FP exceptions
(see Figure below).
The exceptions do not cause traps to facilitate non-speculative out-of-order execution [7].
3.4 The canonical qNaN
The FP standard according to IEEE 754 reserves part of the encoding space for a so-called NaN.
A NaN either represents the result of an invalid operations (qNaN) or an uninitialized value (sNaN).
According to IEEE 754, a NaN is encoded by a value, which has all exponents set to 1, with a non-zero mantissa.
The encoding difference between a qNaN and an sNaN was specified in IEEE 754-2008, stating that the MSB in the mantissa
functions as a quiet bit.
The lax definition of the non-zero mantissa allows to encode information in a NaN, called payload.
For instance, you could use the payload to encode why the operation failed.
But IEEE 754 fails to further elaborate how this should work in detail, so in practice,
I’m not aware of any relevant ISA implementing this feature.
That means, whenever you generate an invalid operation on x64 or RISC-V, the same canonical qNaN is returned for every kind of invalid.
But how does it look like?
Since IEEE 754 doesn’t exactly specify the bit encoding of a canonical qNaN, it came how it had to come.
We are now left with different canonical qNaNs among ISAs:
ISA
Sign
Significand
IEEE 754-2008 compliant
SPARC
0
11111111111111111111111
✓
RISC-V F $< v2.1$
0
11111111111111111111111
✓
MIPS
0
01111111111111111111111
✗
PA-RISC
0
01000000000000000000000
✗
x64
1
10000000000000000000000
✓
Alpha
1
10000000000000000000000
✓
ARM64
0
10000000000000000000000
✓
PowerPc
0
10000000000000000000000
✓
Loongson
0
10000000000000000000000
✓
RISC-V F $\geq v2.1$
0
10000000000000000000000
✓
As you can see in the table, RISC-V initially started with a SPARC-like canonical qNaN.
However, the encoding was changed to ARM64’s NaN as stated at the 3rd RISC-V Workshop [5] in 2016.
This eventually found influence RISC-V ISA manual version 2.1 [21].
So, why did they change it?
According to A. Waterman [7], the new encoding was chosen based on the following arguments:
It is the same NaN as used in ARM64 and Java.
Clearing bits has lower hardware cost than setting bits.
It is the only qNaN that cannot be generated by quieting an sNaN.
The reason behind the third argument is to distinguish propagated from generated NaNs in case of an input sNaN.
Yet, this remains a rather hypothetical argument, as the RISC-V standard does not mandate NaN propagation.
3.5 NaN Boxing
On 2017-03-19, A. Waterman opened a Github issue [22], remarking that the undefined of behavior of FP load and store instructions might lead to problems.
At that time, storing smaller than FLEN FP values did not have a specified memory layout.
For example, if a RISC-V system with F and D extensions loads a 32-bit FP value into register f0, and subsequently stores the register using the FSD instruction, there is no defined memory layout.
It is only guaranteed that loading the value from the same address reinstantiates the intended value.
The undefined memory layouts can be problematic in multiple scenarios, as pointed out by A. Bradburry in his RFC [23] on 2017-03-23.
For example, when migrating tasks on a heterogeneous SoC, each core could interpret the FP register file dump differently.
To solve this problem, A. Bradburry proposed multiple solutions, which were then discussed in the RISC-V ISA-Dev group [24].
Among the most favored and ISA-compliant approaches were:
Store 32-bit FP values in the lower half of a 64-bit register. This approach is used by ARM64.
Cast 32-bit FP values to 64 bit and perform appropriate rounding and masking whenever 32-bit operations are used. Implemented in POWER6 and Alpha.
Encapsulate 32-bit FP values in a 64-bit FP NaN. Not seen in any architecture before.
After discussing arguments of all approaches, the NaN-boxing scheme was ultimately chosen as the solution and added to the specification on 2017-04-13 [22].
This feature saturates upper bits when working on FP data, which is smaller than the architecture’s FP register width FLEN.
If the aforementioned RISC-V system loads a 32-bit FP value, e.g. $2.5$, into register f0, the lower 32 bits of the register represent the FP value, while the upper 32 bits of f0 are set to 1.
Hence, the register f0 reads as 0xffffffff40200000.
Additionally, a 32-bit value is only considered valid if the upper bits are saturated.
Otherwise, the value is interpreted as a negative qNaN.
This approach allows for additional debug information, which is not available in other ISAs.
As with most ISAs, a FP register file dump does not allow to infer the currently saved data types.
However, with NaN boxing, the presence of saturated upper bits allows to determine the data type with high certainty.
Because these special NaN values cannot be produced by standard arithmetic instructions, as NaN propagation is not mandated by RISC-V.
Yet, there is a risk of confusion with dynamically interpreted languages, which often use a software-based NaN boxing for encoding data types.
While NaN boxing might look useful at first glance, it increases fragmentation among ISAs and complicates cross-platform simulation/emulation.
In my recent about fast RISC-V simulation,
Nan boxing is one of 6 reasons why simulating RISC-V on x64 is so complicated and slow.
Lastly, and maybe as interesting remark, OpenRISC 1000 also adopted NaN Boxing in 2019 with version 1.3 [19].
4 Methods
After the first survey-like part, it is now time for the RISC-V FP extensions F/D to stand the test of practice.
The goal was to get a general picture of instruction/data distribution and how often certain cases arise.
Since real hardware is not really suited for this, I extended MachineWare’s RISC-V simulator SIM-V with a profiling FPU.
I then executed a bunch of applications.
For both the applications and SIM-V, I provide a more in-depth explanation in the following two subsections.
4.1 The Applications
The main criterion for the selection of the applications was the use of FP instructions.
Once I found an application with at least a few FP instructions, I included it in my list.
In total, I ran 78 applications, which are given in the list below.
Another concern was that the application should cover a variety of scenarios.
From high-performance computing (linpack [25], NPB [26])
over machine learning (OpenNN [27])
to graphics computation (glmark2 [28]);
a large spectrum of different use cases is reflected in the chosen applications.
This also includes applications written in different programming languages.
Because depending on the language, different peculiarities in the FP arithmetic can arise.
Therefore, I selected benchmarks in
C++ (FinanceBench [29]),
Erlang (smallptr-erlang [30]),
Fortran (NPB[26]),
Java (SciMark 2.0 [31]),
Javascript (Octane 2.0 [32]),
Python (NumPy [33]),
and other programming languages.
In total, the 78 benchmarks executed more than 80 trillion instructions (80,653,539,756,271) of which more than 16 trillion (16,824,921,642,417)
were part of the F/D extensions. The instruction distribution and other interesting stuff are presented in the next section.
To execute the aforementioned 78 applications, I used MachineWare’s RISC-V simulator SIM-V[44].
The simulator was part of Virtual Platform (VP) configured to model a RV64IMAFDC VP with 4GB of main memory.
For most benchmarks, the VP runs an Ubuntu 22.04 operating system.
Some benchmarks run on a minimal buildroot-configured Linux.
The VP was modified to track the number of executed instructions and other data of interest.
To not accidentally track boot or non-benchmark related instructions, the VP was extended by semihosting instructions that allow to reset and dump the statistics.
That means, before the execution of each benchmark, the statistics were reset, which was followed by a dump after the execution finished.
In contrast to compiler-based annotations, as for example in gcov [45], a VP-based approach allows to track every detail, reaching from instructions in the kernel to closed-source libraries.
To really track every tiny detail, softpipe was configured as the system’s graphics driver.
Using softpipe the CPU also executes tasks, which are usually outsourced to the GPU.
If you want to also conduct such a study on your own, you can probably also use an open-source simulator like gem5, Spike, or QEMU.
But please beware, none of them are currently able to track FP details.
So, you’d have to implement this first.
Due to performance reasons I’d recommend to implement this in QEMU.
QEMU also uses callbacks for FP instructions, which should make it relatively easy to add this feature.
5 Related Work
Maybe it is a bit unusual to have the related work section at this point,
but I thought it made sense to place it after explaining the methodologies.
Similar to the structure of this post, it is divided into two parts.
First, I provide literature about the RISC-V ISA design.
Second, I present papers about assessing the characteristics of applications with regards to the host ISA.
As already mentioned in Section 2. Story & Motivation, information about the RISC-V ISA design is spread everywhere -
there is a RISC-V ISA dev Google group [2],
a RISC-ISA manual Github repository [3],
a RISC-V working groups mailing list [4],
and a RISC-V workshop [5].
Furthermore, there are some publications/books from the RISC-V authors themselves:
RISC-V Geneology[6] by T. Chen and D. Patterson, 2016
Design of the RISC-V Instruction Set Architecture[7] by A. Waterman, 2016
The RISC-V Reader: An Open Architecture Atlas[46] by A. Waterman and D. Patterson, 2017
If you want to know why certain aspects of RISC-V are designed the way they are, I can recommend Design of the RISC-V Instruction Set Architecture and The RISC-V Reader: An Open Architecture Atlas.
While these publications already provide many explanations, they are far from complete.
Moreover, at least for the FP part, many of the arguments are of qualitative nature. Not much is backed by actual data or evidence.
And this is where this work begins.
Of course, if some already did such an analysis for the FP extensions, I wouldn’t have done it.
I’m also not aware of literature specifically analyzing the FP parts of other ISAs.
If you increase the scope and just look for papers, which assess aspects like instruction distributions,
you are more successful.
In literature, two approaches are commonly used to assess instruction distributions.
The static analysis approach, as used by [47], [48], simply assesses the instruction occurrences in the binary.
However, the results obtained from this method can be misleading, as the number of occurrences does not necessarily indicate how often an instruction is actually executed.
Moreover, this approach reaches its limitations for self-modifying code and dynamically interpreted languages.
A more accurate and less constrained approach is dynamic analysis, as used in [49], [50], [43].
In dynamic analysis, the instruction distribution is directly obtained from the execution of the benchmark itself.
This can be achieved by counting instructions in a simulator or by using compiler annotations.
The latter has the disadvantage of only counting instructions in the application’s user mode.
Ultimately, the instructions distribution should reflect what is executed on the user’s system, including operating system, drivers,
and other aspects, which are indirectly related to the executed benchmark.
To obtain results that encompass all executed instructions and side effects,
a simulator-based approach, as utilized by my colleague N. Bosbach[49], [43], proves to be one of the few viable methods.
This is why experiments were conducted using a profiling RISC-V simulator.
6 Results & Discussion
6.1 Instruction Distribution
In this subsection, I present and discuss the results of FP instruction distributions in the applications.
Note that I treat 32-bit and 64-bit instructions as one entity.
For example, FLX refers to both FLS (32 bit) and FLD (64 bit).
I also clustered the conversion functions partially.
FCVT.I.F refers to float-to-integer conversions,
FCVT.F.I to integer-to-float conversions,
and FCVT.F.F to float-to-float conversions.
So let’s start with the general results before we move on to the individual benchmarks.
The following graph depicts the instruction distribution accumulated over all benchmarks:
As you can see, the general trend looks like a exponential distribution.
I also put an ideal exponential distribution in the graph (orange line) and it fits surprisingly well.
Surprisingly well with one outlier: FLCASS, which only occurs once every 13,812 FP instructions. But more on that in a few sentences.
Besides that, we also observe a few instructions making up the majority of all executed instructions.
For example, the instructions FLX (32%), and FSX (17%), sum up to nearly 50% of all executed FP instructions.
This in line with the observation of other people.
In an interview with Lex Fridman, Jim Keller, the ISA-god himself, said: “90% of the execution is on 25 opcodes.”.
The contribution of each application to the overall instructions can be inferred from the left Figure below.
As a next step, let us look at the relative distributions for each individual benchmark.
A heatmap depicting the relative distribution of FP instructions per benchmark can be found in the right Figure below.
As already seen in the accumulated distribution, FP store and load instructions are the most prevalent instructions in nearly every benchmark.
This stands in contrast to instructions such as FNMADD, FMIN, FMAX, or FCLASS, which are often not even executed once (gray boxes).
Especially the latter is only present in 12 out of 78 benchmarks.
This raises the question whether such an instruction should be part of a RISC ISA.
To answer this question, you need to consider many aspects, such as the context of instruction, possible alternatives, and impact on performance/hardware cost/encoding space.
And this is where the next subsection begins!
6.2 More on FCLASS
As shown before, the FCLASS instruction occurs infrequently, with many applications not only using it once.
The benchmark glmark2-bump attains the highest relative value, with 0.0909% of all instructions being FCLASS.
Besides being present in all glmark benchmarks, it also occurs in FinanceBench and 507.cactuBSSN.
Since FCLASS can appear in different contexts, I investigated the reasons for its use in the applications.
For all(!) applications, I could track down all(!) usages of the FCLASS instruction to glibc’s fmax/fmin function.
The corresponding C implementation for 32-bit FP is depicted in the following code:
Here, you would intuitively expect only a RISC-V fmax instruction, yet there are additional checks for sNaNs.
This is due to RISC-V adhering to the IEEE 754 standard from 2019 in that regard, where the maximum of an sNaN and numerical value must return the latter.
In glibc, however, this operation has to return a qNaN, making it compliant with older IEEE 754 standards.
To rectify this mismatch, additional checks and treatments for sNaN is needed.
As explained by David G. Hough [51], converting qNaN to sNaN in minimum/maximum functions, as in glibc and older IEEE 754 standards,
was a bug in the specification and entails awkward mathematical properties.
The bug fix from IEEE 754-2019 is not yet present in glibc.
And I’m not sure if it ever will be present.
Other C standard libraries, such as musl[52] or Newlib[53],
directly map fmax and fmin to the underlying ISA implementations inheriting their NaN-handling characteristics.
That means, if the applications are linked against musl or NewLib instead of glibc, the number of executed FCLASS instructions can be reduced to 0.
Or in other words, using this approach, FCLASS does not occur once in 78 benchmarks executing trillions of instructions.
Also, just recently the RISC-V “Zfa” (Additional Floating-Point Instructions) extension was specified.
This extension provides backward compatible maximum and minimum instructions (FMINM, FMMAXM), allowing us to implement glibc’s fmax and fmin without FCLASS.
Anyway, let us assume we might want to remove this instruction from the RISC-V ISA.
This means, that at least at some points we have to replace the FCLASS instruction with other instructions that achieve the same semantics.
The important question is: Do we need 1, 10, or 100 instructions to mimic the same behavior?
Interestingly, in the case of FCLASS, it is probably not necessary to aim for a bit-exact reproduction.
As mentioned by A. Waterman [7], the purpose of FCLASS is to branch if exceptional values, such as NaN,
are encountered.
The code below shows both a typical assembly context for detecting sNaN using FCLASS:
As can be seen, a typical check for a certain FP type using FCLASS requires 3 instructions.
First, FCLASS returns the value type in a one-hot encoding, then the type of interest is extracted by bitmasking, and finally a branch is taken depending on the previous result.
So, Alexander and I tried our best and coded some FLCASS-less alternatives, as shown in the following code:
// generic zero // positive zero // negative zerofmv.w.xf1,x0fmv.x.wx1,f0fneg.sf0,f0feq.sx1,f1,f0bezx1,is-p-zerofmv.x.wx1,f0bnezx1,is-zerobezx1,is-n-zero// generic NaN // quiet NaN // signaling NaNfeq.sx1,f0,f0fmv.x.wx1,f0feq.sx1,f0,f0beqzx1,is-nanluix2,0x7fc00fmv.x.wx2,f0andx1,x1,x2bextix2,x2,22beqx1,x2is-qnanorx1,x1,x2beqzx1,is-snan// generic infinity // positive infinity // negative infinityfli.sf1,inffli.sf1,influix1,0x8f800fabs.sf0,f0feq.sx1,f1,f0fmv.w.xf1,x1feq.sx1,f1,f0bnezx1,is-p-inffeq.sx1,f1,f0bnezx1,is-p-infbnezx1,is-n-inf// generic normal // positive normal // negative normalfmv.x.wx1,f0fli.sf1,inffmv.x.wt0,f0luix2,0x7f800fli.sf2,minbgtzt0,not-normandx3,x2,x1flt.sx1,f0,f1luit1,0x7f800beqzx3,is-not-normfle.sx2,f2,f0andt0,t0,t1beqx3,x2is-not-normandx1,x1,x2beqzt0,not-normbnezx1,is-normalbeqt0,t1,not-norm// generic subnormal // positive subnormal // negative subnormalfabs.sf0,f0fmv.w.xf1,x0fnegf0,f0fmv.w.xf1,x0fli.sf2,minfmv.w.xf1,x0fli.sf2,minflt.sx1,f1,f0fli.sf2,minflt.sx1,f1,f0flt.sx2,f0,f2flt.sx1,f1,f0flt.sx2,f0,f2bnezx2,is-subnflt.sx2,f0,f2bnezx2,is-subnbnezx2,is-subn
With Standard extensions only:
// generic zero // positive zero // negative zerofmv.w.xf1,x0fmv.x.wx1,f0fneg.sf0,f0feq.sx1,f1,f0bezx1,is-p-zerofmv.x.wx1,f0bnezx1,is-zerobezx1,is-n-zero// generic NaN // quiet NaN // signaling NaNfeq.sx1,f0,f0fmv.x.wx1,f0feq.sx1,f0,f0beqzx1,is-nanluix2,0x7fc00fmv.x.wx2,f0andx1,x1,x2luix3,0x00400beqx1,x2is-qnanandx3,x3,x2orx1,x1,x3beqzx1,is-snan// generic infinity // positive infinity // negative infinityluix1,0x7f800luix1,0x7f800luix1,0x8f800fmv.w.xf1,x1fmv.w.xf1,x1fmv.w.xf1,x1fabs.sf0,f0feq.sx1,f1,f0feq.sx1,f1,f0feq.sx1,f1,f0bnezx1,is-p-infbnezx1,is-n-infbnezx1,is-p-inf// generic normal // positive normal // negative normalfmv.x.wx1,f0fmv.x.wt0,f0fmv.x.wt0,f0luix2,0x7f800bltzt0,not-normbgtzt0,not-normandx3,x2,x1luit1,0x7f800luit1,0x7f800beqzx3,is-not-normandt0,t0,t1andt0,t0,t1beqx3,x2is-not-normbeqzt0,not-normbeqzt0,not-normbeqt0,t1,not-normbeqt0,t1,not-norm// generic subnormal // positive subnormal // negative subnormalfmv.w.xf1,x0fmv.w.xf1,x0fmv.w.xf1,x0fabsf0,f0luix1,0x00800luix1,0x80800luix1,0x00800fmv.w.xf2,x1fmv.w.xf2,x1fmv.w.xf2,x1flt.sx1,f1,f0flt.sx1,f1,f0flt.sx1,f1,f0flt.sx2,f0,f2flt.sx2,f0,f2flt.sx2,f0,f2andx1,x1,x2andx1,x1,x2andx1,x1,x2bnezx1,is-subnbnezx1,is-subnbnezx1,is-subn
The first code block includes instructions from the B and Zfa extension, which might not be present on many systems.
So, the second block only includes instructions from the standard extensions.
To test the functionality of the code, I embedded it in a C++ test environment, which you can download here.
Interestingly, if FCLASS is not used, some cases can be achieved with even less instructions (see positive zero, or generic NaN).
For example, we can exploit that comparisons with NaN values always return false, allowing us to check for their presence in only one instruction.
Similar to FCLASS, all instructions used in the code are also lightweight and do not require any data memory accesses.
So, let’s assume we’d remove FCLASS from the ISA/FPU. What would be the associated saving in terms of hardware?
Fortunately, the hardware expert Lennart
was there to help me synthesize designs.
Using Synopsys ASIP designer and a 28nm/32nm TSMC standard cell library, he designed a 3-stage RV32IMF processor with and without FCLASS.
Ultimately, the FCLASS instruction accounted for ~0.25% of the FPU’s area, excluding register file.
That’s not much, but in comparison to its relative execution share of 0.0072%, still a considerable amount.
To conclude, I recommend reconsidering the role of FCLASS in the RISC-V ISA.
I personally feel like the best place for FCLASS is the quite recent “Zfa” (additional FP instructions).
With that, it’s not part of the really basic FP stuff, but if you need all that corner-case-fancy FP things, you can still add it with “Zfa”.
I also believe Intel came to the same conclusion, which is why FP-related extensions after x87 do not include this instruction.
It’s also not present in ARM64, which I interpret as another argument for this conclusion.
6.3 Subnormal Numbers & Underflows
Now to one the of most controversial features of the IEEE 754 standard [54]:
subnormal numbers and gradual underflows.
On the one hand, subnormal numbers bring numerically advantageous properties like Sterbenz’ lemma [55],
on the other hand, they increase hardware cost, and their implementation is considered the most challenging task in FPU design [56].
As shown by numerous works, handling subnormal numbers can reduce a FPU’s attainable throughput by more than $100\times$ [57], [58], [59].
Due to this possible performance degradation, Intel introduced the so-called FTZ mode with the release of SSE in 1999 [60].
This mode allows to flush subnormal numbers to zero, increasing the performance of applications with non-critical accuracy requirements like real-time 3D applications.
Such a mode is also present in ARM64 (FPSCR:FZ), but you don’t find it in RISC-V!
How often subnormal numbers and underflows occur in practice is not stated in any of the aforementioned works.
Also other works only provide anecdotal evidence and statements like “gradual underflows are uncommon” [61].
So, let me remedy this circumstance using the profiling VP.
The following graph depicts the relative share of underflows for applications with at least one underflow:
The results confirm that underflows and subnormals are rather an exception than the norm.
Out of 78 benchmarks, 59 did not raise a single underflow exception or have a single subnormal in-/output operand.
The highest share of underflows occurs in MiBench susan with 0.48% of all arithmetic FP instructions underflowing.
Accumulated over all benchmarks, underflows occurred once every 7992 arithmetic FP instructions, with subnormal in-/outputs every 3875/4427 operands.
Hence, only a fraction of FP applications would benefit from an FTZ mode.
To what extent performance can be increased, ultimately depends on the hardware implementation and application.
To get some coarse idea, you can run the subnormal arithmetic evaluation benchmark by Dooley et al. [57].
On my x64 laptop (Intel(R) Core(TM) i5-8265U CPU), I get a slow-to-fast factor of 11.28.
To test some RISC-V hardware, I ran the same benchmark on StarFive’s VisionFive 2.
Surprsingly, the results showed no performance degradation due to subnormal arithmetic!
It even handles subnormal arithmetic faster than the laptop I’m currently using to write this blog post.
So why is that?
I cannot say it with 100% confidence, but I guess the underlying VisionFive 2 FPU is Berkley’s Hardfloat [62]
or at least some derivative of it.
This FPU uses a special recoded format [20], enabled by RISC-V’s separate registers for FP arithmetic,
to facilitate fast subnormal calculation.
How did I come to this conclusion?
Starfive’s Visionfive uses an SoC called JH7110.
This incorporates multiple U74 cores from SiFiVe.
Andrew Waterman and Yunsup Lee, the founding members of SiFive, are among the top contributors for this project.
Ultimately, the decision not to endow RISC-V with a FTZ mode, as in ARM64 or x64, seems reasonable in my opinion.
6.4 Exponent Distribution
Although the IEEE 754 binary floating point is the most widespread approximation of real numbers in computing, other formats can be considered as well.
An often discussed alternative is the posit format introduced by the famous computer scientist J. L. Gustafson in 2017 [63].
Opposed to IEEE 754’s quasi-uniform accuracy, posit exhibits a tapered accuracy centered around 1, which is qualitatively depicted in the following figure:
According to many works, most values in practical applications are centered around 1.
Consequently, posit should accumulate less error in many benchmarks.
Or to provide some quotes:
“Close to the number 1, posits have better precision than floating point. This is useful because numbers close to 1 are very common.” [64]
“Posits have superior accuracy in the range near one, where most computations occur.” [65]
“Worst-case precision is highest where the most common numbers are, in the center of the range of possible exponents.” [66]
“For the most common values in the range of about 0.01 to 100, posits have higher accuracy than IEEE floats and bfloats, but less accuracy outside this dynamic range.” [67]
Interestingly, the claimed centering around 1 is not substantiated with data in any of the sources mentioned.
This is only derived from the observed lower rounding error of posit.
So it is time to bring some light into the darkness with the profiling FPU!
To do this, I recorded the exponent distribution of the in- and outputs for all arithmetic 64-bit instructions.
After executing all 78 applications, the following picture emerged (the blue line represents the average, while each of the faint colors is an individual benchmark):
Please note that only the exponents of subnormal and normal numbers were assessed, i.g. NaNs and infinities were excluded.
As you can see, most applications and also the average are indeed centered around a magnitude of $2^{0} = 1$ with a gaussian-like distribution.
In that regard, the results speak for posit.
To get some more differentiated conclusions, I redrew the graph with a logarithmic Y axis:
This graph reveals a distribution, which is skewed towards smaller exponents.
So maybe, having some sort of negatively-shifted exponent could help prevent underflows, without risking too many infinities 🤔.
I guess someone already did it, but I couldn’t find any literature about that topic.
To conclude, just looking at the topic from a mathematical point of view, posit seems to be a better number representation for the majority of the applications.
Maybe some inofficial RISC-V extensions, like Xposit [68], might find their way into the official specification one day.
6.5 Mantissa Distribution
RISC-V and most other ISAs use a radix of 2 for their FP arithmetic.
But why not use a radix of 3, 4, or 10?
While radix 10 has some advantages in terms of representing human everyday life numbers,
the highest average accuracy is achieved with radix 2.
If you are interested in the deeper theoretical background of this conclusion,
I can highly recommend the Handbook of Floating-Point Arithmetic[69].
One important thing about proving the superiority of radix 2, is assuming a logarithmic mantissa distribution.
At least from a theoretical perspective, this assumption is fine.
As shown by R. W. Hamming, [70] arithmetic operations transform various mantissa input distributions to a logarithmic distribution.
But how about a practical assessment?
The following graph depicts the mantissa distribution for all benchmarks.
Again, the blue line represents the average, while the faint colors represent individual benchmarks.
Note that I distributed the mantissa into 256 different bins.
The linear graph is not really meaningful, so here’s the same data with a logarithmic Y-axis.
I also added an ideal logarithmic distribution, which is represented by the thick orange line.
Except some outliers here and there, the ideal distribution comes really close to the measurements.
To conclude, choosing radix 2 doesn’t seem to be the worst decision.
6.6 Rounding Modes
Whenever FP stuff is computed, rounding errors might occur.
There’s not really a way to avoid them, but at least we can direct them in one or the other way.
This can be achieved by means of rounding modes of which IEEE 754 standard defines the following:
roundTiesToEven (mandatory)
roundTiesToAway (introduced in 2008, not mandatory)
roundTowardPositive (mandatory)
roundTowardNegative (mandatory)
roundTowardZero (mandatory)
I guess the names are quite self-explanatory. For example, roundTowardPositive will always round a value towards positive infinity.
The most common rounding mode for arithmetic is roundTiesToEven.
With that rounding mode, the result is always rounded to the nearest representable values.
If there are two nearest values, the result is rounded towards the even ones.
Following the IEEE 754 standard, RISC-V also implements these five rounding modes.
As already mentioned in Subsubsection 2) Conversions and Rounding and Subsection 3.3 The Registers,
there are two ways to make use of rounding modes.
The first one is by specifying the rounding mode in an instructions.
Many F/D instructions have a dedicated 3-bit field for that as shown in the following excerpt from the RISC-V ISA manual [21]:
The second option is to specify “dynamic” the instruction, which then uses the rounding mode as specified in the register FPCSR.
So, why have two ways when one suffices?
As described in Design of the RISC-V Instruction Set Architecture[7],
the design of the rounding mode things follow the design of most programming languages.
For instance, in C++ you can set a dynamic rounding mode for following arithmetic floating point operations with std::fesetround.
So pretty much the way FPCSR works.
But additionally, you have non-dynamic parts.
For example, casting a float value to an integer always uses roundTowardZero.
So, in that case, having the rounding mode statically encoded in the instruction is beneficial.
But how often does which case arise?
Again, I couldn’t find any literature, so I consulted my profiling VP.
Using the VP, I tracked the rounding modes under which each instruction was executed.
For the conversion instructions (float to int, int to float, etc.), the following distribution emerged:
roundTiesToEven: 0.843
roundTowardZero: 0.045
roundTowardNegative: 0.056
roundTowardPositive: 0.056
roundTiesToAway: 4.92e-05
As you can see, roundTiesToEven is the most frequent rounding mode, while roundTiesToAway is rarely seen.
Now to arithmetic instructions (addition, multiplication, etc.):
roundTiesToEven: 1.0
roundTowardZero: 0.0
roundTowardNegative: 0.0
roundTowardPositive: 0.0
roundTiesToAway: 0.0
Yes, you see it correctly.
Out of 7,290,823,332,047 arithmetic FP instructions, not a single one used a non-default rounding mode!
So, why is that?
Or the better question is: Why would you use a non-default rounding mode?
roundTiesToEven already gives you the smallest error, so there’s not much reason to change it.
One of the very few applications of non-default rounding modes is interval arithmetic.
Using interval arithmetic, you try to determine an upper and a lower bound for your result.
For example, when adding two numbers, the lower bound is given by roundTowardNegative, while the upper bound is given by roundTowardPositive.
The correct result is somewhere in between.
An implementation of interval arithmetic in C++ is the boost interval library[71].
Besides interval arithmetic, I couldn’t find any compelling reasons for non-default rounding in arithmetic instructions.
Ultimately, just telling from my data, having a statically encoded rounding mode in arithmetic FP instructions doesn’t make sense.
If I’m missing an important aspect, please contact me!
7 Conclusion & Outlook
In this work, I showed how a modified RISC-V VP can be used to analyze the characteristics of the RISC-V FP extensions F and D.
In total, the VP executed more than 16 trillion FP instructions of 78 applications, precisely tracking the distribution of FP of instructions, FP mantissa, FP exponent, and frequency of underflows.
Overall, I think the F/D extension is well-thought-out, but if I had the change to redesign it from scratch, I’d reconsider the following things:
The FCLASS instruction seemed to be heavily underutilized. Maybe the “Zfa” extension is a more appropriate place for it.
Non-default rounding modes for arithmetic FP instructions are extremely rare. Maybe the static rounding mode encoding in the instruction can be removed.
Besides the RISC-V-specific things, I learned the following about FP in practice:
Most FP data is centered around a magnitude of 1
Underflows are rare
Loads and stores and seem to be the most common FP operations
Having IEEE 754 is nice, but 2 revisions and lax definitions have lead to a significant fragmenation among ISAs
Most ISAs don’t really fully adhere to IEEE 754 because it mandates too many instructions
One major ISA characteristic not analyzed in this work is the number of optimal registers.
Here, the VP could be modified to track the register pressure of FP registers during the execution.
But this post is already long enough, so maybe I will address it in future work.
If you found any bugs/typos or have some remarks, feel free to write me a mail.
I also welcome any kind of discussion 🙂.
8 References
[1]L. Jünger, J. H. Weinstock, and R. Leupers, “SIM-V: Fast, Parallel RISC-V Simulation for Rapid Software Verification,” DVCON Europe 2022, 2022.
[2]“RISC-V ISA Dev Google Group.” [Online]. Available at: https://groups.google.com/a/groups.riscv.org/g/isa-dev
[3]“RISC-V ISA Manual Github Repository.” [Online]. Available at: https://github.com/riscv/riscv-isa-manual
[4]“RISC-V Working Groups Mailing List.” [Online]. Available at: https://lists.riscv.org/g/main
[6]T. Chen and D. A. Patterson, “RISC-V Geneology,” EECS Department, University of California, Berkeley, Tech. Rep. UCB/EECS-2016-6, 2016.
[7]A. Waterman, “Design of the RISC-V Instruction Set Architecture,” 2016.
[8]A. Waterman, Y. Lee, D. A. Patterson, and K. Asanovic, “The RISC-V Instruction Set Manual, Volume I: Base User-Level ISA, Version 1,” EECS Department, UC Berkeley, Tech. Rep. UCB/EECS-2011-62, vol. 116, 2011.
[9]“IEEE Standard for Floating-Point Arithmetic,” IEEE Std 754-2008. IEEE, 2008.
[10]“IEEE Standard for Floating-Point Arithmetic,” IEEE Std 754-2019 (Revision of IEEE 754-2008). IEEE, 2019.
[11]A. Waterman, Y. Lee, D. A. Patterson, and K. Asanovic, “The RISC-V Instruction Set Manual, Volume I: User-Level ISA, Version 2.2,” 2017.
[12]“IEEE Standard for Binary Floating-Point Arithmetic,” ANSI/IEEE Std 754-1985. IEEE, 1985.
[18]IBM, “PowerPC User Instruction Set Architecture Book I Version 2.01.” 2003.
[19]OPENRISC.IO, “OpenRISC 1000 Architecture Manual - Architecture Version 1.3.” 2019 [Online]. Available at: https://raw.githubusercontent.com/openrisc/doc/master/openrisc-arch-1.3-rev1.pdf
[20]J. R. Hauser, “HardFloat Recoding.” [Online]. Available at: www.jhauser.us/arithmetic/HardFloat-1/doc/HardFloat-Verilog.html
[21]A. Waterman, Y. Lee, D. A. Patterson, and K. Asanovi, “The RISC-V Instruction Set Manual, Volume I: User-Level ISA, Version 2.1,” California Univ Berkeley Dept of Electrical Engineering and Computer Sciences, 2016.
[22]A. Waterman, “NaN Boxing Github Issue.” [Online]. Available at: https://github.com/riscv/riscv-isa-manual/issues/30
[23]A. Bradbury, “NaN Boxing RFC.” [Online]. Available at: https://gist.github.com/asb/a3a54c57281447fc7eac1eec3a0763fa
[25]“linpack.” [Online]. Available at: https://www.netlib.org/linpack/
[26]“NAS Parallel Benchmarks.” [Online]. Available at: https://www.nas.nasa.gov/software/npb.html
[27]“OpenNN Examples.” [Online]. Available at: https://github.com/Artelnics/opennn/tree/master/examples
[28]“glmark2.” [Online]. Available at: https://github.com/glmark2/glmark2
[29]“FinanceBench.” [Online]. Available at: https://github.com/cavazos-lab/FinanceBench
[30]“smallpt.” [Online]. Available at: https://github.com/matt77hias/smallpt
[31]“SciMark 2.0.” [Online]. Available at: https://math.nist.gov/scimark2/
[32]“Octane 2.0.” [Online]. Available at: https://github.com/chromium/octane
[33]“NumPy benchmarks.” [Online]. Available at: https://github.com/numpy/numpy/tree/main/benchmarks
[34]“SPEC CPU 2017.” [Online]. Available at: https://spec.org/cpu2017/
[35]J. Walker, “fbench.” [Online]. Available at: https://www.fourmilab.ch/fbench/fbench.html
[36]J. Walker, “ffbench.” [Online]. Available at: https://www.fourmilab.ch/fbench/ffbench.html
[37]“whetstone.” [Online]. Available at: https://netlib.org/benchmark/whetstone.c
[38]“STREAM benchmark.” [Online]. Available at: https://www.cs.virginia.edu/stream/
[39]“c-ray.” [Online]. Available at: https://github.com/jtsiomb/c-ray
[40]S. Fujita, “aobench.” [Online]. Available at: https://github.com/syoyo/aobench
[41]“Himeno Benchmark.” [Online]. Available at: https://github.com/kowsalyaChidambaram/Himeno-Benchmark
[42]“CoreMark®-PRO.” [Online]. Available at: https://github.com/eembc/coremark-pro
[43]M. R. Guthaus, J. S. Ringenberg, D. Ernst, T. M. Austin, T. Mudge, and R. B. Brown, “MiBench: A free, commercially representative embedded benchmark suite,” in Proceedings of the Fourth Annual IEEE International Workshop on Workload Characterization. WWC-4 (Cat. No.01EX538), 2001, pp. 3–14, doi: 10.1109/WWC.2001.990739.
[44]L. Jünger, J. H. Weinstock, and R. Leupers, “SIM-V: Fast, Parallel RISC-V Simulation for Rapid Software Verification,” DVCON Europe 2022.
[45]“gcov.” [Online]. Available at: https://gcc.gnu.org/onlinedocs/gcc/Gcov.html
[46]D. Patterson and A. Waterman, The RISC-V Reader: An Open Architecture Atlas, 1st ed. Strawberry Canyon, 2017.
[47]A. Akshintala, B. Jain, C.-C. Tsai, M. Ferdman, and D. E. Porter, “X86-64 Instruction Usage among C/C++ Applications,” in Proceedings of the 12th ACM International Conference on Systems and Storage, New York, NY, USA, 2019, pp. 68–79, doi: 10.1145/3319647.3325833 [Online]. Available at: https://doi.org/10.1145/3319647.3325833
[48]A. H. Ibrahim, M. B. Abdelhalim, H. Hussein, and A. Fahmy, “Analysis of x86 instruction set usage for Windows 7 applications,” in 2010 2nd International Conference on Computer Technology and Development, 2010, pp. 511–516, doi: 10.1109/ICCTD.2010.5645851.
[49]N. Bosbach, L. Jünger, R. Pelke, N. Zurstraßen, and R. Leupers, “Entropy-Based Analysis of Benchmarks for Instruction Set Simulators,” in RAPIDO2023: Proceedings of the DroneSE and RAPIDO: System Engineering for constrained embedded systems, New York, NY, USA, 2023, pp. 54–59, doi: 10.1145/3579170.3579267.
[50]“Analysis of X86 Instruction Set Usage for DOS/Windows Applications and Its Implication on Superscalar Design,” in Proceedings of the International Conference on Computer Design, USA, 1998, p. 566.
[51]D. G. Hough, “The IEEE Standard 754: One for the History Books,” Computer, vol. 52, no. 12, pp. 109–112, 2019, doi: 10.1109/MC.2019.2926614.
[52]“musl.” [Online]. Available at: https://musl.libc.org/
[53]“Newlib.” [Online]. Available at: https://sourceware.org/newlib/
[54]W. M. Kahan and C. Severance, “An Interview with the Old Man of Floating-Point.” [Online]. Available at: https://people.eecs.berkeley.edu/ wkahan/ieee754status/754story.html
[55]P. H. Sterbenz, “Floating-point computation,” 1973.
[56]E. M. Schwarz, M. Schmookler, and S. D. Trong, “FPU implementations with denormalized numbers,” IEEE Transactions on Computers, vol. 54, no. 7, pp. 825–836, 2005, doi: 10.1109/TC.2005.118.
[57]I. Dooley and L. Kale, “Quantifying the interference caused by subnormal floating-point values,” Jan. 2006.
[58]J. Bjørndalen and O. Anshus, “Trusting Floating Point Benchmarks - Are Your Benchmarks Really Data Independent?,” 2006, pp. 178–188, doi: 10.1007/978-3-540-75755-9_23.
[59]M. Wittmann, T. Zeiser, G. Hager, and G. Wellein, “Short Note on Costs of Floating Point Operations on current x86-64 Architectures: Denormals, Overflow, Underflow, and Division by Zero,” Jun. 2015.
[60]S. Thakkur and T. Huff, “Internet Streaming SIMD Extensions,” Computer, vol. 32, no. 12, pp. 26–34, 1999, doi: 10.1109/2.809248.
[61]W. M. Kahan, “Lecture Notes on the Status of IEEE Standard 754 for Binary Floating-Point Arithmetic.” [Online]. Available at: https://people.eecs.berkeley.edu/ wkahan/ieee754status/IEEE754.PDF
[62]J. R. Hauser, “Berkley Hardfloat Github Repository.” [Online]. Available at: https://github.com/ucb-bar/berkeley-hardfloat
[63]J. Gustafson and I. Yonemoto, “Beating Floating Point at its Own Game: Posit Arithmetic,” Supercomputing Frontiers and Innovations, vol. 4, pp. 71–86, Jun. 2017, doi: 10.14529/jsfi170206.
[64]Loyc, “Better floating point: posits in plain language.” [Online]. Available at: http://loyc.net/2019/unum-posits.html
[65]Wikipedia, “Wikipedia - Unum (Number Format).” [Online]. Available at: https://en.wikipedia.org/wiki/Unum_(number_format)
[66]J. Gustafson, “Posit arithmetic,” Mathematica Notebook describing the posit number system, 2017.
[67]A. Guntoro et al., “Next Generation Arithmetic for Edge Computing,” in 2020 Design, Automation and Test in Europe Conference and Exhibition (DATE), 2020, pp. 1357–1365, doi: 10.23919/DATE48585.2020.9116196.
[68]D. Mallasén, R. Murillo, A. A. Del Barrio, G. Botella, L. Piñuel, and M. Prieto-Matias, “PERCIVAL: Open-Source Posit RISC-V Core With Quire Capability,” IEEE Transactions on Emerging Topics in Computing, vol. 10, no. 3, pp. 1241–1252, 2022, doi: 10.1109/TETC.2022.3187199.
[69]J.-M. Muller et al., Handbook of Floating-Point Arithmetic. 2010.
[70]R. W. Hamming, “On the distribution of numbers,” The Bell System Technical Journal, vol. 49, no. 8, pp. 1609–1625, 1970, doi: 10.1002/j.1538-7305.1970.tb04281.x.
[71]Boost, “Boost interval.” [Online]. Available at: https://github.com/boostorg/interval
This is another post of my TLMBoy series where I document the development of my equally named Game Boy Emulator.
In contrast to my other posts, the following sections do not deal with any “How do I implement this and that?”.
I rather dissect and explain the 256-byte hidden boot code that helps bringing up the Game Boy!
When turning on most compute systems, only a few things are guaranteed to have a certain value. The Game Boy is no exception and only guarantees the program counter register to be initialized with 0.
All other things like other registers, the sound processor, and the pixel processing unit have to be initialized by the boot process.
In case of the Game Boy, the boot code resides within a special 256-byte ROM that is mapped from 0x00 to 0xff.
Interestingly, the boot ROM unmaps itself from the memory map after finishing the boot.
This demap feature made it quite hard to reverse engineer the boot code.
The first successful reverse engineering attempt was achieved by a dude(tte) called “neviksti” in 2003. This was 14 years after the initial release of the Game Boy in 1989!
According to gbdev wiki [1] this person was actually mad enough decap the Game Boy’s SoC and read out every single bit using a microscope.
Interestingly neviksti’s website [2] is still up today and features some cool die shots like this one:
If you are interested in reading and interpreting bits of a ROM I can highly recommend this tutorial.
In the following sections, I’ll go through the boot code line by line and analyze it.
Furthermore, I’ll try to disassemble the assembly into some C-ish code.
Of course I’m a little bit late to the party and a lot of people wrote some nice wrapups before me. Take a look at the Literature to see what helped me writing this post.
Also Nintendo themselves helped me
by putting their boot CFG (control flow graph) into a patent [3] called
“System for preventing the use of an unauthorized external memory”:
2. The Boot Code
Before analyzing the code, we do of course need some assembly code to work on!
My personal favorite is this [4] commented, human-readable boot rom which I will refer to in the following.
2.1 BB0: Init Regfile
The first three instructions are some plain register initializations.
The stack pointer sp is set to 0xfffe; register a is set to 0; and hl now points to the VRAM (0x9fff).
BB0:
0x000 ld sp, $fffe // init stack
0x003 xor a // efficient way for: a = 0
0x004 ld hl, $9fff // set hl to VRAM
2.2 BB1: Init the VRAM
To avoid displaying random garbage, the Game Boy has to zero-initialize its VRAM.
The following three-line loop takes care of it.
BB1:
0x007 ld [hl-], a // load a into [hl], then decrement hl
0x008 bit 7, h // stop condition
0x00a jr nz, @BB1 // jump to BB1, if not zero
This quite dense code can be achieved by using a little bit-trick.
The VRAM ranges from 0x8000 to 0x9FFF, whereby all these addresses in binary
have a “1” bit at position 8 in the MSB.
But the first number under 0x8000 doesn’t:
The same functionality can be achieved with the following C-Code:
for(inti=0x9FFF;i>=0x8000;--i){mem[i]=0;}
2.3 BB2: Init the sound
The next lines setup the Game Boy’s sound processor:
0x00c ld hl, rNR52 // load 0xFF26 into hl: register no 52
0x00f ld c, $11
0x011 ld a, $80
0x013 ld [hl-], a // rNR52 = $80, all sound on
0x014 ld [c], a // rNR11 = $80, wave duty 50%
0x015 inc c
0x016 ld a, $f3
0x018 ld [c], a // rNR12 = $f3, envelope settings
0x019 ld [hl-], a // rNR51 = $f3, sound output terminals
0x01a ld a, $77
0x01c ld [hl], a // rNR50 = $77, SO2 on, full volume, SO1 off, full volume
These lines setup the square wave channel for the iconic boot “bling bling” sound.
I try not to get lost in details, as this setup is of minor relevance for the boot process.
A corresponding C-Code could look like this:
mem[0xff26]=0x80;// All sound on.mem[0xff11]=0x80;// Square wave: Wave duty 50%, don't use length register.mem[0xff12]=0xf3;// Square wave: Start at full volume (15), and then decrement every 3 envelope ticks until 0.mem[0xff25]=0xf3;// Sound output terminal.mem[0xff24]=0x77;// SO2 on, full volume, SO1 off, full volume
2.4 BB3: Init the color palette
As a next step, the background and window color palette register (BGP, at 0xff47) is set to 0b11111100,
and the pointers for logo load are prepared.
0x01d ld a, $fc
0x01f ldh [rBGP], a // BGP = $fc, set up color palette
0x021 ld de, $0104 // de = cartridge header logo
0x024 ld hl, $8010 // hl = VRAM
The BGP setup can be translated as:
11 10 01 00 # value
| | | |
11 11 11 00 # mapped to
| | | |
b b b w # b=black, w=white
It’s simply a remapping of color values for the background and window tiles.
So, for a example, a pixel with the a value of 01 is displayed as 11, which is deep black
(the reason for this mapping is explained in Subsection 2.7)
The corresponding C-Code is just (ignoring the pointers):
mem[0xff47]=0xfc;// set up BG and window color palette
2.5 BB4: Load the Logo
The job of the next basic block is to load the Nintendo logo from the cartridge into the VRAM:
BB4:
0x027 ld a, [de] // for loop over cartridge logo data, de = 0x104
0x028 call $0095 // copy cartridge logo data to VRAM at $8010
0x02b call $0096
0x02e inc de
0x02f ld a, e
0x030 cp $34 // a == 0x34?
0x032 jr nz, @BB4
However, due to size constraints, the Nintendo logo is heavily compressed and needs to be decompressed by a relatively simple algorithm.
That way the 48 Bytes of the compressed Nintendo logo can be inflated to 384 Bytes (=24 tiles) worth of pixel data.
The corresponding C-Code looks like this:
u8*vram=0x8010;for(u8*logo=0x0104;logo<0x0134;++logo){u8data=*logo;DecompressAndCopy(data,vram);vram+=4;DecompressAndCopy(data>>4,vram);vram+=4;}// vram will be 80d0
In the following section, we will take a closer look at the decompression algorithm.
2.6 Decompress And Copy
The decompression algorithm of the Game Boy is not really complex, yet the assembly is quite:
// 'a' holds the next datum of the logo
DecompressAndCopy:
0x095 ld c, a // c = 76543210
0x096 ld b, $04 // loop counter
decomp_loop:
0x098 push bc
0x099 rl c
0x09b rla
0x09c pop bc
0x09d rl c
0x09f rla
0x0a0 dec b
0x0a1 jr nz, @decomp_loop
0x0a3 ld [hl+], a
0x0a4 inc hl // leave on byte blank
0x0a5 ld [hl+], a
0x0a6 inc hl // leave on byte blank
0x0a7 ret
So, let’s start with an abstract description of what the algorithm actually does.
As an input, the algorithm receives one byte of data (the numbers represent bit positions):
> in = 76543210
The output is then a scaled version (2x in x and y direction) distributed over 4 bytes:
I hope that this is as simple as I promised.
We now increase the difficulty and analyze the actual implementation.
The first call of the DecompressAndCopy calculates the first two bytes of the outputs (out0, out1),
while the second call calculates the last two bytes (out2, out3).
Note, that the second call uses 0x96 instead of 0x95 as an entry point due intermediate values still residing in register c.
To more make the code more accessible, I did a systematic analysis of the decomp_loop.
In the following table, each column represents an iteration of the decomp_loop, whereby the numbers uniquely identify
the bits (C stands for carry):
instr
b = 4
b = 3
b = 2
b = 1
0x99
c=6543210x, C=7
c=54321076, C=6
c=43210754, C=5
c=32107532, C=4
0x9b
a=65432107, C=7
a=43210776, C=5
a=21077665, C=3
a=07766554, C=1
0x9c
c=76543210
c=65432107
c=54321075
c=43210753
0x9d
c=65432107, C=7
c=54321075, C=6
c=43210753, C=5
c=32107531, C=4
0x9f
a=54321077, C=6
a=32107766, C=4
a=10776655, C=2
a=77665544, C=0
Note, how the carry is used in very clever way to exchange bits between the c and the a register.
Creating some functionally similar C-code may look like this:
The C-code above is functionally equal,
yet barely resembles the original assembly as there’s no way to utilize carry bits in C.
2.7 Registered Trademark
In contrast to the Nintendo logo, the registered trademark logo doesn’t need any decompression.
Furthermore, it’s fetched from the boot ROM, not from the cartridge!
Hence, it’s simply loaded into the memory as follows:
0x034 ld de, $00d8 // de = boot rom data after logo
0x037 ld b, $08 // b = length of data
reg_trade:
0x039 ld a, [de]
0x03a inc de
0x03b ld [hl+], a // hl points to VRAM
0x03c inc hl
0x03d dec b
0x03e jr nz, @-$07 // 8 iterations
Note, that we leave, similarly to the previous section, one byte blank again.
Usually, each pixel displayed comprises two bits spread over different bytes.
But due to our custom color mapping (only black and white), the second bit doesn’t really
carry any information and is thus left blank.
More information about how pixel data is represented will be provided in my soon-to-appear PPU post.
If one would render the tile map at this state, the following image would show up:
Most of the tilemap is just empty space, but the 25 tiles used to depict the Nintendo logo are already
more than recognizable!
2.8 Selecting the Right Tiles
Due to its memory limitations, the Game Boy doesn’t really have a pixel-wise buffer of the whole screen.
Instead, it uses a tile-based system usually referring to 8x8 tiles via 32x32 byte pointers.
A more in-depth explanation will be provided in my yet to be written post about the PPU.
So for now this has to suffice ;)
Anyway, the decompression algorithm we already saw just drew some tiles into the tile data map.
But the information about where to draw these tiles is provided with the following lines:
0x040 ld a, $19 // select tile 25
0x042 ld [$9910], a // display tile 25 at (8,16)
0x045 ld hl, $992f // point to (9,15)
BB48:
0x048 ld c, $0c // c = 12
BB4a:
0x04a dec a
0x04b jr z, @BB55
0x04d ld [hl-], a
0x04e dec c
0x04f jr nz, @BB4a
0x051 ld l, $0f // point to tile (8,15)
0x053 jr @BB48
BB55:
The code initializes the display tiles from (9,3-15) and from (8,3-15) using a nested loop.
A corresponding C code:
At this point, the only thing yet to be configured is the PPU (Pixel Processing Unit).
So, we could draw anything in the tile buffer, but we would never see a pixel without a turned-on display.
The following lines take care of that:
BB55:
0x055 ld h, a // h = 0
0x056 ld a, $64
0x058 ld d, a // d = 100
0x059 ldh [rSCY], a // scroll_y = 100
0x05b ld a, $91 // 0x91 = 0b10010001
0x05d ldh [rLCDC], a // [0xff40] = b10010001
Most of the configuration is done at instruction 0x5d.
This instruction writes data into a PPU configuration register resulting in the following setup:
1 = turn on LCD screen
0 = window tile map 0x9800-$9bff
0 = window display off
1 = bg and window tile data = 0x8800-0x97ff
0 = bg tile map 0x9800-0x9bff
0 = obj sprite size 8*8
0 = obj sprite display off
1 = bg and window display on
The Y scrolling is set up as well with a value of 100.
This is iteratively decremented to achieve the scroll-down effect of the Nintendo logo.
The C-Code is quite simple for this part:
Ok, now everything is set up and it’s time to scroll down the Nintendo logo:
// h = 0
0x05f inc b // b = 1
BB60:
0x060 ld e, $02 // e = 2; 2MC
BB62:
0x062 ld c, $0c // c = 12; 2MC
BB64:
0x064 ldh a, [rLY] // a = [0xff44] vline number; 2MC
0x066 cp $90 // a == 144?; 1MC
0x068 jr nz, @BB64 // 2MC/3MC
0x06a dec c // 1MC
0x06b jr nz, @BB64 // 2MC/3MC
0x06d dec e // 1MC
0x06e jr nz, @BB62 // 2MC/3MC
0x070 ld c, $13
0x072 inc h
0x073 ld a, h
0x074 ld e, $83
0x076 cp $62
0x078 jr z, @BB80
0x07a ld e, $c1
0x07c cp $64
0x07e jr nz, @BB86
BB80:
0x080 ld a, e
0x081 ld [c], a
0x082 inc c
0x083 ld a, $87
0x085 ld [c], a
BB86:
0x086 ldh a, [rSCY]
0x088 sub b
0x089 ldh [rSCY], a // scroll_y -= 1
0x08b dec d
0x08c jr nz, @BB60
0x08e dec b
0x08f jr nz, @BBE0 // Jump to Nintendo Logo check, 0xe0
0x091 ld d, $20
0x093 jr @-$35 // BB60
However, before any configuration data of a running PPU is touched, the Game Boy needs to make sure that the PPU isn’t rendering at the moment.
This actually very short period of idling is either indicated by a v-blank interrupt
or by a LY-register (residing at 0xff44) value of greater or equal than 144..
Apparently, the Game Boy engineers chose the latter option.
They implemented a busy waiting method that constantly polls the LY register
and compares its value against 144 (see instructions 0x64-0x68).
The code doesn’t look really obvious at first glance, so let’s take a closer look.
We’ll start at the inner loop beginning at BB64 which just waits for the v-blank register to return a 144.
Once this happens, two nested loops, from now on called e-loop and d-loop due to their loop variables, with loop counts of 2 and 12 are started.
Note, that in each iteration we’re still asking the v-blank register if it’s still at 144!
But how long does it keep that value?
According to the Game Boy CPU Manual [7] the v-blank register increases its value every 114 machine cycles (MC).
So, the Game Boy has 114 machine cycles worth of instructions to spend before the 144 turns into a 145.
These 114 machine cycles are more or less one iteration of the e-loop!
Here’s the calculation:
1 c-loop iteration = 2+1+2+1+3 = 9MC
12 iterations whereby the last one is only 8 cycles: 11*9+8 = 107MC
Plus e-loop part: 107+6 = 113MC
Note, that depending on the result (branch or not branch)
the jump instructions either take 3 or 2 machine cycles respectively.
After the first e-loop iteration the Game Boy has to wait for a whole frame ~17ms until the v-blank
register exposes as 144 again.
Therefore, the instructions from 0x60 to 0x6e can be summarized as: wait for two frames and finish with an idle PPU.
The next few instructions play the iconic “bling bling” sound and most importantly: they scroll down the Nintendo logo by one pixel!
This scroll effect is achieved by changing the value of the scroll-y register. Its value determines the window’s offset in pixels in y-direction.
Since this whole part is wrapped into a bigger loop (the d-loop), the Game Boy decreases the scroll-y register 100 times.
Taking the two frames wait period into account, we arrive at roughly 3 seconds for the Nintendo logo scroll-down sequence.
This pretty much complies with the real-word behaviour.
After the logo reached its final position it rests there for a short period of time. This is achieved by instructions
0x08e to 0x93. These instructions reduce the scroll increment to 0 (dec b) and then run the whole d-loop again for 32 times.
In the end, the rendered result of my TLMBoy looks like this:
As usual, here’s the C-code of the current sequence:
intd=100;inth=0;for(intd=100;d>0;--d){// wait for 2 framesfor(inte=2;i>0;--i){for(intc=12;j>0;--j){while(vline()!=144){}}}h++;u16*sound_f_low;u16*sound_f_high;sound_f_low=0xFF13;sound_f_high=0xFF14;e=0x83;if(h==98){gotoBB80;}e=0xc1;if(h!=100){gotoBB86;}BB80:*sound_f_low=e;// "e" is first 0x83 (a C6 note) and then 0xc1 (a C7 note).*sound_f_high=0x87;BB86:*scroll_y-=1;}// let the logo rest a short timefor(intd=32;d>0;--d){for(inte=2;i>0;--i){for(intc=12;j>0;--j){while(vline()!=144){}}}}
2.11 Checking the logo
After the scroll sequence, the Game Boy verifies whether it was really a Nintendo logo that showed up on your screen.
If it’s not, the boot loader just bricks.
As explained in [8], this was Nintendo’s way of preventing unlicensed game developers from publishing games for the Game Boy.
Because you cannot forbid someone to develop games for your hardware, but you can sue people for using your logo!
This check is done byte by byte from instruction 0x0e0 to 0x0ef.
The last instruction finally unloads the boot ROM by writing a 1 into address 0xFF50.
BBE0:
0x0e0 ld hl, $0104 // hl = rom cartridge header logo
0x0e3 ld de, $00a8 // de = boot rom logo
BBE6:
0x0e6 ld a, [de] // for loop over the cartridge header logo
0x0e7 inc de
0x0e8 cp [hl]
BBE9:
0x0e9 jr nz, @BBE9 // loop forever if fail
0x0eb inc hl
0x0ec ld a, l
0x0ed cp $34
0x0ef jr nz, @BBE6
0x0f1 ld b, $19
0x0f3 ld a, b
BBF4:
0x0f4 add [hl] // for loop through the rest of the header to calculate checksum, CODE XREF=CopyData+98
0x0f5 inc hl
0x0f6 dec b
0x0f7 jr nz, @BBF4
0x0f9 add [hl] // Validate against the cartridge header checksum field
BBFA:
0x0fa jr nz, @BBFA // If header checksum is invalid then loop forever
0x0fc ld a, $01
0x0fe ldh [$ff00+$50], a
// (0x95-0xa7): Decompress and copy the data to VRAM.voidDecompressAndCopy(u8data,u8*addr){u8mask0=0b00000001;u8mask1=0b00000011;u8res=0;for(inti=0;i<4;++i){res|=(data&mask0)?mask1:0;mask0<<=1;mask1<<=2;}*addr=res;*(addr+2)=res;}voidmain(){// BB1 (0x07-0x0a) : Setting up the VRAM.u8*mem=0x0;for(inti=0x9FFF;i>=0x8000;--i){mem[i]=0;}// BB2 (0x0c-0x1c): Setting up the sound.mem[0xff26]=0x80;// All sound on.mem[0xff11]=0x80;// Square wave: Wave duty 50%, don't use length register.mem[0xff12]=0xf3;// Square wave: Start at full volume (15), and then decrement every 3 envelope ticks until 0.mem[0xff25]=0xf3;// Sound output terminal.mem[0xff24]=0x77;// SO2 on, full volume, SO1 off, full volume.// BB3 (0x1d-0x24): Init the color palette.mem[0xff47]=0xfc;// Set up BG and window color palette.// BB4 (0x27-0x32): Load the logo.u8*vram=0x8010;for(u8*logo=0x0104;logo<0x0134;++logo){u8data=*logo;DecompressAndCopy(data,vram);vram+=4;DecompressAndCopy(data>>4,vram);vram+=4;}// (0x34-3e): Load the registered trademark.u8*vram=0x80d0;for(u8*logo=0xd8;logo<0xe0;++logo){*vram=*logo;vram+=2;}// (0x40-0x53): Selecting the right tiles.inta=25;u8*mem=0x9910;*mem=a;mem=0x992f;for(intj=0;j<2;++j){for(inti=12;i>0;--i){a--;*mem=a;mem--;}mem=0x990f;}// (0x55-0x5d): Display init.u8*rSCY=0xff42;*rSCY=100;u8*rLCDC=0xff40;*rLCDC=0x91// (0x5f-0x93): Showtime.intd=100;inth=0;for(intd=100;d>0;--d){// Wait for 2 frames.for(inte=2;i>0;--i){for(intc=12;j>0;--j){while(vline()!=144){}}}h++;u16*sound_f_low;u16*sound_f_high;sound_f_low=0xFF13;sound_f_high=0xFF14;e=0x83;if(h==98){gotoBB80;}e=0xc1;if(h!=100){gotoBB86;}BB80:*sound_f_high=e;*sound_f_high=0x87;BB86:*scroll_y-=1;}// Let the logo rest a short time.for(intd=32;d>0;--d){for(inte=2;i>0;--i){for(intc=12;j>0;--j){while(vline()!=144){}}}}// (0xe0-0xfe) Checking the logo.*cartridge_logo=0x104*boot_logo=0xa8for(inti=0;i<48;++i){if(cartridge_logo[i]!=boot_logo[i]){while(true){};// Loop forever.}}*cartridge_header=0x134sum=0x19;for(inti=0;i=<25;++i){sum+=cartridge_header[i];}if(sum!=0){while(true){};// Loop forever.}unload_boot_rom();return;}
4. Trivia
Despite being a fascinating and well-designed program,
the boot ROM actually leaves some room for circumventing the logo check.
Since the logo is loaded twice from the cartridge (one time for the VRAM, a second time for the check),
providing the right data at the right time let’s you boot up the Game Boy without infringing any copyrights.
This is achieved by first providing a custom logo for the scroll-up part, and then providing a Nintendo logo for the logo check.
Of course, you need some custom logic in your cartridge to detect what kind of data is currently requested.
Nevertheless, some companies used this exploit to sell some unlicensed games (see [9]).
5. Conclusion
I hope you enjoyed this “little” post about the Game Boy’s boot process.
Even though the boot ROM is just a 256-byte program (with a significant part of just logo data),
it somehow suffices to write a more-than-3000-words blog post about it.
I guess this shows how much you can achieve with a little of assembly if you know how to do your job well.
Especially the decompress and copy process is a good example of it.
I doubt that any compiler could attain the same code density.
If there’s any feedback, don’t hesitate to contact me :)
6. References
[1] Gameboy Development Wiki [2] neviksti’s website [3] Game Boy patent [4] Commented boot ROM [5] Boot ROM tutorial 1 (detailed) [6] Boot ROM tutorial 2 [7] Game Boy CPU manual [8] History of boot ROM and logo generator [9] Custom boot logos
In this post, I’ll cover how I implemented the GDB Serial Protocol (GDBRSP) for my Game Boy simulator TLMBoy.
For the whole code in action see gdb_server.cpp and gdb_server.h in my Github repo.
While I used the Game Boy as a target architecture, the principles and details presented here can be applied to every other platform as well.
In fact, you just need a GDB for your desired CPU architecture!
Since the Game Boy’s CPU (basically a Z80 clone) isn’t natively supported by GDB, I’ll show you how to get a Z80 GDB first.
If you don’t mind the extra work, you could also extend GDB by adding support for your favorite architecture.
But in the case of the Z80, someone already went ahead ;)
2. Motivation
Before we dive into the technical details, let’s answer some simple yet important questions first:
2.1 What is GDBRSP?
GDB Remote Serial Protocol (GDBRSP) is the name of the protocol that GDB
uses to communicate with so-called GDBstubs.
The protocol defines how packets have to look and how servers and clients communicate.
As a backbone usually either the TCP protocol or just a plain serial communication is employed.
Extensive documentation can be found in the GDB docs
2.2 What is it good for?
Because why don’t we just use plain GDB to debug stuff?
Imagine you’re programming a Game Boy simulator like in my case.
You end up with is a piece of software (a Game Boy simulator) that executes another piece of software (for instance Pokémon Red).
To debug your simulator, you’d probably just use GDB, which is perfectly fine.
But how do you debug the software inside the software (Pokémon Red) from the Game Boy’s perspective?
One common approach is to incorporate a so-called GDBstub into your simulator.
This stub receives messages from GDB, for example, via TCP, and translates them to simulator specific instructions as depicted in the following illustration:
Implementing this stub for your specific simulator requires some work by you, which is mainly covered in this post.
But trust me, having a GDBstub in your simulator is a really cool feature.
Because once you have your stub, you can just use the typical GDB frontend and start your debug sessions.
This is why many well-known simulators like QEMU or gem5
also have implemented their own GDBstub.
Before I explain the details on implementing a Game Boy GDBstub, let’s
take a look at how to get a GDB with Z80 (the Game Boy’s CPU) support first.
If you already have one, feel free to skip the next section.
Note: you can also my TLMBoy’s docker container,
which includes said Z80 GDB (start it with z80-unknown-elf-gdb).
3. Getting Z80 GDB
I guess you probably already consulted google searching for a Z80 GDB, which might have led you to the following Github repository.
However, most of this code is more than 10 years old, and compiling it is a pain in the *** if you’re using a quite recent Linux
environment.
As it happens to be, a few months ago (September 2020), some cool guy submitted a patch to the GDB team, including architecture support for Z80 CPUs and even the Game Boy’s modified version.
But as stated in the given link, it might take a while until this patch is upstream.
And I guess adding support for an antiquated architecture isn’t really the first item on the maintainers’ priority list…
So, in the meanwhile, let’s just compile it ourselves!
Fortunately, the glorious Z80 patcher provided a Github repository which can be found
here.
The next steps are just cloning the repository and building that stuff as follows:
git clone https://github.com/b-s-a/binutils-gdb.git
cd binutils-gdb
mkdir build
./configure --target=z80-unknown-elf --prefix=$(pwd)/build --exec-prefix=$(pwd)/build
make
make install
Depending on your preferences, you may want to change things like the build directory or the executable format.
Since the Game Boy doesn’t really have an executable format, I just took elf, but other file formats like coff should work as well.
At that point, you should find an executable Z80 GDB in the bin directory:
4 Exploring the Protocol
4.1 General Considerations
In this section, we’ll take a closer look at the protocol and what GDB expects from us.
As already mentioned, I want to implement a GDBstub for my Game Boy simulator.
Depending on your GDBstub, you might have to meet different design considerations at some points.
For example, my first few steps were implementing a TCP server (which is not covered in this post),
but if you’re implementing a GDBstub for some embedded device, a serial connection might be a better choice.
Anyway, let’s get down to business!
The typical GDBRSP packet uses the following pattern:
$packet-data#checksum
It comprises a “$” to indicate the beginning of a packet, some packet data, usually human-readable,
and a two-digit hex checksum that is preceded by a “#”.
For instance, a packet may look like this:
$m0,8#01
In this case m0,1 tells us to read 8 bytes beginning at memory location 0.
The checksum is calculated by summing up the ASCII values of each character of the packet data (“$” and “#” are excluded!)
and taking the first 8 bits of the results (corresponds to modulo 256). Or to formulate it as C++ code:
In theory, verifying the checksum doesn’t make sense from our stub’s perspective as the TCP protocol already has some error detection under the hood. But for the sake of completeness, I implemented it anyway.
Controlling the checksum is one thing, but how does one check if the message is syntactically correct?
The messages used by GDB are pretty simple and don’t contain any nested structures.
Hence, I used a big chonky regex to detect all the packets that I want to support:
Besides the standard packet, there is also an acknowledge packet + and a not-acknowledge packet -.
Every message transmitted via GDBRSP needs a response in the form of + or -.
With that in mind, let’s take a look at some first packets that GDB sends to a stub when initiating a connection!
4.2 First Contact
To do this, we first need to set up a TCP client. You can program a TCP client, or just a Linux network tool like netcat.
For instance:
netcat -l 1337
This starts a TCP client listening on port 1337.
As a second step, GDB has to be started and connected, which can be achieved with the following commands:
z80-unknown-elf-gdb
(gdb) set arch gbz80
(gdb) set debug remote 1
(gdb) target remote localhost:1337
With set arch gbz80, we tell GDB to switch to the modified Z80 instruction set that is used by the Game Boy.
I also added the set debug remote 1 to make GDB more verbose and provide us with some interesting insights.
The connection is finally established with target remote localhost:1337.
If everything goes well, netcat should output the TCP messages sent by GDB.
Let’s analyze them in the next section!
4.3 qSupported
The first packet which arrives at our GDBstub looks as follows:
Using the gdb docs, let’s break down the message into its substantial parts.
With qSupported (gdbdocs), GDB tries to tell us about all the fancy features it supports.
This message is not only a statement, but it’s also asking the stub about which features it supports.
So let’s take a look at the single parameters and try to contemplate which one we need:
multiprocess: Indicates support of the multiprocess extensions. However, the Game Boy doesn’t really have multiple processes, so there’s no need to support it.
swbreak: Indicates support of software breakpoint stop reason.
With a software breakpoint, you basically replace the instruction with another instruction that triggers some behavior detected by the debugger. I chose not to support this as hardware breakpoints are a simpler alternative.
hwbreak: Indicates support of hardware breakpoint stop reason. Hardware breakpoints use special hardware registers that trigger some behavior if, for instance, a specified program counter value is reached.
This is quite easy to implement in a simulator, so I chose to support this.
qRelocInsn: Indicates support for relocating instructions, a feature needed for so-called tracepoints. Tracepoints aren’t really interesting for use, so skip them.
fork-events: The Game Boy doesn’t have an OS. Consequently, there are no
child processes (forks) to debug. Skip it.
vfork-events: Pretty similar to fork-events. Skip it.
vexec-events: Indicates support of the Linux execve command. Again there’s not really an OS, so we’ll skip that one.
vContSupported: Indicates support for vCont. Might be useful if your system supports multiple threads, which isn’t the case for the Game Boy. Skip it.
QThreadEvents: Again thread-related stuff which we can skip.
no-resumed: More thread-related stuff … skipped.
So, we only support hardware breakpoints. Consequently, the answer looks like this:
In general, the minimum set of commands and features that a GDBstub needs to support is relatively small.
The gdb docs state:
At a minimum, a stub is required to support the ‘?’ command to tell GDB the reason for halting, ‘g’ and ‘G’ commands for register access, and the ‘m’ and ‘M’ commands for memory access. Stubs that only control single-threaded targets can implement run control with the ‘c’ (continue) command, and if the target architecture supports hardware-assisted single-stepping, the ‘s’ (step) command. Stubs that support multi-threading targets should support the ‘vCont’ command. All other commands are optional.
4.4 vMustReplyEmpty
After sending our response, GDB immediately sends another packet to our stub:
$vMustReplyEmpty#3a
According to the docs, this command tests how our server responds to unknown packets (vMustReplyEmpty is not defined by definition).
The correct response to an unknown packet is an empty response:
$#00
Apparently, some older stubs would incorrectly respond with an ‘OK’ to unknown packets. To test this, vMustReplyEmpty was introduced.
The C++ code looks as follows:
GDB doesn’t get tired of sending us packets responding directly with a:
$Hg0#df
With this command, all following ‘g’ commands (read register) refer to the thread of the given thread id.
However, thread id ‘0’ is a special case, as can be read in the gdb docs:
A thread-id can also be a literal ‘-1’ to indicate all threads, or ‘0’ to pick any thread.
Since this command is not in the minimum set, and we don’t have multiple threads, we can send an empty response (command unknown) again:
$#00
4.6 qTStatus
The next incoming packet is:
$qTStatus#49
GDB is asking us whether a trace experiment is currently running.
Well, we’re not supporting tracing anyway, so respond empty:
$#00
4.7 ?
With the ‘?’ packet, GDB asks for a reason why the target halted.
Since we’re stopping our process once GDB connects, we have to reply with one of the responses listed in
gdb docs.
I felt like the following response was a good choice:
$S05#b8
Here ‘S05’ responds to POSIX signal SIGTRAP. It’s the typical signal being triggered when running into a software breakpoint, often leading to a halt.
For instance, qemu uses the same signal in its stub.
Also the guy from this cool tutorial uses SIGTRAP.
Since the Game Boy doesn’t really have an OS, it doesn’t have POSIX signals as well.
Hence, it’s more like a dummy answer to satisfy gdb. In theory, using any other signal number should work as well.
The C++ looks as follows:
GDB seems to be happy with our ‘S05’ response and sends us the following packet afterward:
$qfThreadInfo#bb
With that packet, GDB is asking us about which threads are active.
We’ll just respond empty as we’re not supporting threads:
$#00
GDB is really persistent about threads and sends us the predecessor of the qfThreadInfo packet:
$qL1160000000000000000#55
Gues what we respond?
$#00
The next incoming packet is:
$Hc-1#09
This packet is similar to the ‘Hg’ packet and indicates that all following ‘c’ packets refer to all threads (-1).
Let’s respond with empty response as we haven’t changed our opinion about threads in the meanwhile.
The subsequent packet asks for the current thread ID:
$qC#b4
… Insert generic statement about threads here …
4.9 qAttached
GDB seems to be unstoppable and proceeds with the following packet:
$qAttached#8f
Here we have to respond either with ‘1’ indicating that our remote server is attached to an existing process
or with a ‘0’ indicating that the remote server created a new process itself.
Depending on our answer here, we either get a kill or detach command when invoking ‘quit’.
Since I want to keep the Game Boy running even when quitting GDB, the appropriate answer is ‘1’:
$1#31
4.10 g
The next packet received is:
$g#67
Here GDB wants to read our CPUs registers.
The documentation provides more information about the respone format:
Each byte of register data is described by two hex digits. The bytes with the register are transmitted in target byte order. The size of each register and their position within the ‘g’ packet is determined by the GDB internal gdbarch functions
DEPRECATED_REGISTER_RAW_SIZE and gdbarch_register_name.
When reading registers from a trace frame (see Using the Collected Data), the stub may also return a string of literal ‘x’’s in place of the register data digits, to indicate that the corresponding register has not been collected; thus its value is unavailable.
This means, in order to put the correct register value in the correct place, I have to search through GDB’s source code…
I feel like this is not a well-conceived solution, especially if multiple debuggers are used with each having a different ordering of the registers.
It would be better if there was some kind of message to define the layout,
or if the GDB team would just establish a standard per ISA.
Anyway, I followed down the function gdbarch_register_name in z80_tdep.c until I found the corresponding array:
// Frame 2set_gdbarch_register_name(gdbarch,z80_register_name);// Frame 1/* Return the name of register REGNUM. */staticconstchar*z80_register_name(structgdbarch*gdbarch,intregnum){if(regnum>=0&®num<ARRAY_SIZE(z80_reg_names))returnz80_reg_names[regnum];returnNULL;}// Frame 0staticconstchar*z80_reg_names[]={/* 24 bit on eZ80, else 16 bit */"af","bc","de","hl","sp","pc","ix","iy","af'","bc'","de'","hl'","ir",/* eZ80 only */"sps"};
Hence, our response will start with the “af” registers and then progress until the “pc” registers.
Any subsequent registers are omitted due to the reduced registers set of the Game Boy’s Z80.
Melting this into C++ code may look like this:
Please note that the Z80 is a little-endian system requiring us to send the LSB first.
Hence the usage of this amazing new C++-20 Feature std::rotl.
An example response may look like this one here:
Here only the stack pointer is initialized (SP=0xfffe) while all other registers are 0.
5 Connection Established
After answering more than 10 packets, GDB finally seems to be satisfied and offers me its terminal!
See the debug log:
(gdb) target remote localhost:1337
Remote debugging using localhost:1337
Sending packet: $qSupported:multiprocess+;swbreak+;hwbreak+;qRelocInsn+;fork-events+;vfork-events+;exec-events+;vContSupported+;QThreadEvents+;no-resumed+#df...Ack
Packet received: swbreak+;
Packet qSupported (supported-packets) is supported
Sending packet: $vMustReplyEmpty#3a...Ack
Packet received:
Sending packet: $Hg0#df...Ack
Packet received:
Sending packet: $qTStatus#49...Ack
Packet received:
Packet qTStatus (trace-status) is NOT supported
Sending packet: $?#3f...Ack
Packet received: S05
Sending packet: $qfThreadInfo#bb...Ack
Packet received:
Sending packet: $qL1160000000000000000#55...Ack
Packet received:
Sending packet: $Hc-1#09...Ack
Packet received:
Sending packet: $qC#b4...Ack
Packet received:
Sending packet: $qAttached#8f...Ack
Packet received: 1
Packet qAttached (query-attached) is supported
warning: No executable has been specified and target does not support
determining executable automatically. Try using the "file" command.
Sending packet: $g#67...Ack
Packet received: 000000000000000000000000xxxxxxxxxxxxxxxxxxxxxxxxxxxx
Sending packet: $qL1160000000000000000#55...Ack
Packet received:
0x00000000 in ?? ()
(gdb)
Yet we are not done, as some of the mandatory GDB commands aren’t implemented (like G, m, M, s, and c).
I think the best way to explore them is to regard them in the context of GDB terminal commands.
Hence, let’s start with some basic commands such as info registers and then work our way up to stuff like setting breakpoints.
5.1 Reading Registers
The command info registers prints out the values of the CPUs registers:
(gdb) info registers
af 0x0 [ ]
bc 0x0 0
de 0x0 0x0
hl 0x0 0x0
sp 0xfffe 0xfffe
pc 0x0 0x0
ix <unavailable>
iy <unavailable>
af' <unavailable>
bc' <unavailable>
de' <unavailable>
hl' <unavailable>
ir <unavailable>
As you might see in the debug log, there’s actually no message being sent!
This is due to gdb already having all information thanks to ‘g’ that was used to establish the connection.
5.2 Displaying Assembly
With display/5i $pc GDB shows us the next 5 assembly instructions:
The debug log reveals that this command comprises a bunch of m packets.
For instance, the first incoming packet looks like this:
$m0,1a#5b
A quick lookup in the docs reveals that GDB wants to read a chunk of size 0x1a from memory location 0x00.
Nothing easier than that. Let’s code some reply:
voidGdbServer::CmdReadMem(conststd::vector<std::string>&msg_split){std::stringmsg_resp;std::stringaddr_str=msg_split[1];std::stringlength_str=msg_split[2];uintaddr=std::stoi(addr_str,nullptr,16);uintlength=std::stoi(length_str,nullptr,16);for(uinti=0;i<length;++i){u8data=cpu_->ReadBusDebug(addr+i);msg_resp.append(fmt::format("{:02x}",data));}DBG_LOG_GDB("reading 0x"<<length_str<<" bytes at address 0x"<<addr_str);msg_resp=Packetify(msg_resp);tcp_server_.SendMsg(msg_resp.c_str());}
5.3 Step Instruction
As a next typical GDB command, we’ll take a look at si, which is short for step instruction and tells
our program to execute the next assembly instruction.
So, let’s just take a look at the debug log and see what happens:
As you can see, the first few packets are multiple memory reads at different addresses.
These reads are issued as GDB wants to know the instructions that follow after the current one.
At first, I was like: “Why doesn’t gdb just only read program counter + 1?”
Well, the next instruction to be executed isn’t necessarily the one at the next program counter address!
For example, in case of return instructions GDB has to backtrack this next instruction by unwinding the call stack.
This finally explains why GDB read that 32 bytes beginning from 0xFFE0 (the current stack pointer at that time)
and the following instruction (program counter was 0x0 at that time).
Warning: There are some cases in which this command might blow up.
See section Final Thoughts for more information.
The next packet sent is a ‘Z’ packet telling us to insert a software breakpoint (=0) with kind 8 at address 0x3.
But… didn’t we tell GDB that we don’t support software breakpoints in the initialization phase?
Well, I tried to reject that packet, but this then led to no breakpoint being inserted at all.
At this point, I was a little unsure about how to proceed and implement stuff.
So, I took a look at other emulators/simulators/frameworks,
namely qemu,
gem5
and vcml,
and they all do it the same way:
Every kind of breakpoint, be it software or hardware, is mapped onto some kind of virtual hardware breakpoint.
For instance, qemu:
This method is quite easy to implement and avoids changing the memory’s content.
We just insert a given address into a data structure, for example a set, and do a check in the simulator’s main loop whether we reached one of the breakpoints.
This lead me to the following implementation:
voidGdbServer::CmdInsertBp(conststd::vector<std::string>&msg_split){std::stringmsg_resp="";if(msg_split[1]=="0"||msg_split[1]=="1"){msg_resp="OK";uintaddr=std::stoi(msg_split[2],nullptr,16);DBG_LOG_GDB("set breakpoint at address 0x"<<msg_split[2]);bp_set_.insert(addr);}else{DBG_LOG_GDB("watchpoints aren't supported yet");}msg_resp=Packetify(msg_resp);tcp_server_.SendMsg(msg_resp.c_str());}
After the breakpoint was set, GDB tells us to continue execution with the ‘c’ packet.
My implementation of that is quite simple:
Our CPU will now continue its execution until it encounters a breakpoint which is already the next instruction in case of si.
We tell GDB about this event by sending a SIGTRAP signal:
We then get asked to return the current register data (‘g’) and to remove the current breakpoint (‘z’).
Removing the breakpoint is pretty much the same as inserting it, just vice versa:
voidGdbServer::CmdRemoveBp(conststd::vector<std::string>&msg_split){std::stringmsg_resp="";if(msg_split[1]=="0"||msg_split[1]=="1"){msg_resp="OK";uintaddr=std::stoi(msg_split[2],nullptr,16);DBG_LOG_GDB("removed breakpoint at address 0x"<<msg_split[2]);bp_set_.erase(addr);}else{DBG_LOG_GDB("watchpoints aren't supported yet");}msg_resp=Packetify(msg_resp);tcp_server_.SendMsg(msg_resp.c_str());}
After that, only a few memory reads follow, and this is it!
6. Demo: Custom Logo
Nothing beats a fancy demo,
so I made a video showing how you can use GDB to boot up the Game Boy with a custom logo:
In the video I used the following command to start the TLMBoy:
./tlmboy -r ../roms/tetris.bin --wait-for-gdb
To attach GDB to the simulation, use:
target remote localhost:1337
Once GDB is attached, the simulation halts at PC=0x0, and you are free to throw in some commands.
In my case I want to replace the Nintendo logo with my own custom logo.
The logo resides at address 0x104 and upwards, hence I replace this data:
As seen in the video, a high-quality “CHCIKEN” logo is rendered instead of the Nintendo logo.
However, changing the boot logo results in a bricked boot process.
The logo keeps being displayed, but it doesn’t advance past this point.
This is Nintendo’s way of preventing the execution of non-licensed games
(see my boot post for more information).
So, I pressed Ctrl + C and called display/7i $pc to examine the situation.
It can be seen that the Game Boy is stuck in the loop which compares the logo in the cartridge against
the logo in the boot ROM.
The easiest way to resolve this awkward situation is to skip the check.
With GDB, this can be achieved by advancing the program counter a few instructions:
set $pc = 0xfc
Alternatively, you can reload the Nintendo logo shortly before the check starts (your custom logo will remain displayed):
So, in this post I covered the basics of GDB remote serial protocol (GDBRSP) and how once can embed it into a Game Boy emulator (or any application).
Due to the enormous scope of GDBRSP, this post just scratched the surface.
Nevertheless, I hope that it provides a good starting for further adventures.
Last but not least, I still want to share some limitations, questions, and thoughts that came across my path during the development.
Let’s start with the limited debugability of the Game Boy’s ROMs.
These are basically a chunk of handcrafted assembly that doesn’t require any specific file format or underlying operating system.
Consequently, there are no such things as debug symbols or calling conventions that could be used by the debugger.
In some cases, I even observed crashes as GDB was trying to unwind call stacks, that weren’t really call stacks.
For instance, if you execute step instruction directly after connecting, GDB (or my TLMBoy) will say “goodbye”.
This is because GDB tries to determine the callstack with a stack pointer that points to 0,
leading to multiple, seemingly random reads to non-mapped addresses.
Unfortunately, there’s not much one can do about it except avoiding commands that lead to undefined behavior.
Another thing that I didn’t consider at first, but later needed some problem solving, were bank switches.
These are used to circumvent the 64kiB limit imposed by the Game Boys 16-bit address bus.
With bank switching, some parts of the ROM are switched out by other parts of the ROM, which weren’t directly accessible prior to the switch.
This mechanism is triggered by writing a specific value in a specific location.
But in debug mode, I might want to write to certain locations to alter the memory’s value, not to trigger a bank switch.
So, how can I distinguish between bank switch and actual memory write?
The best solution I could come up with, are so-called custom queries. These can invoked with
monitor data from the GDB terminal.
As the name implies, a custom query can convey a custom message that triggers a custom behavior in the stub.
Actually, this is so versatile that probably many other problems can be solved with it as well.
So, this finally concludes my post.
If there’s any feedback, be it good or bad,
feel free to contact me.
8. References
[1]
GDB’s online documentation. The first address to consult when questions about GDBRSP packets arise. [2]
QEMU and GDBRSP. [3]
gem5 and GDBRSP. [4]
Quite old Github repository containing a GDB with Z80 support. [5]
Discussion about the most recent Z80 GDB patch. [6]
Most up-to-date Z80 GDB Github repository. [7] Super detailed and user-oriented post about GDBRSP. [8] Cool blog post about the GDBRSP.
Heyho! Welcome to the first post of my series "TLMBoy", which is about writing a Game Boy Emulator with SystemC TLM-2.0.
So, if you always wanted to write a GameBoy Emulator or learn SystemC TLM-2.0, you found the right place!
I guess writing a Game Boy emulator is nothing innovative (there are currently more than 2000 Game Boy emulators on Github)
and writing Software with SystemC isn't exiciting either.
But to the best of my knowledge, no one ever tried to combine these two!
The result of my attempt can be found in my
Github Repository.
There's no need to worry if you don't know what SystemC is, or have no clue how a Game Boy works.
The only prerequisite is some C++ knowledge as SystemC is library for C++.
This means you should definetely know what a pointer is, but you don't need to pull off some quadruple-singleton-polymorphic-macro C++ stunts.
Also some really basic knowledge of computer architecture is assumed.
The following tutorials will use Linux as an operating system.
However, all dependencies we are using are also available for Windows, so this should work out as well in theory.
Nevertheless, rather than running on native Windows,
I recommend installing WSL, which is a Microsoft-made emulator for Linux on Windows.
Literature, Tutorials, other Emulators
Before we begin with anything technical, I want to clarify that most of the Game Boy's technical details and interna presented in
this post series are from third-party sources. It's now more than thirty years since the release of the initial Game Boy,
and a lot of people spend a lot of time reverse-engineering, writing emulators, or creating tests in their spare time!
Most of this work is a valuable source of information that makes programming a Game Boy emulator quite enjoyable.
The most complete summary of anything Game Boy emulator related can be found in
this Github repo (awesome-gbdev).
Besides that, I often used the gbemu Github as a reference implementation.
This open-source emulator was pretty helpful at some points, especially when I had very detailed questions about certain things.
Anyway, I guess most people know what a Game Boy is, but not many have heard of SystemC yet, so let's get started with a short introduction to SystemC.
SystemC TLM-2.0
Behind the ominous term SystemC there is actually only a simple library for C++.
I have the impression that it is often sold more like a language based on C++ rather than a library.
The reason is probably SystemC's extensive use of super-duper fancy C++ makros resulting in code which might seem unfamiliar at first.
For example, take a look at this code from SystemC's Wikipedia article:
SC_MODULE(adder){// module (class) declarationsc_in<int>a,b;// portssc_out<int>sum;voiddo_add(){// processsum.write(a.read()+b.read());//or just sum = a + b}SC_CTOR(adder){// constructorSC_METHOD(do_add);// register do_add to kernelsensitive<<a<<b;// sensitivity list of do_add}};
As you can see, there's a lot of macro magic going on there.
For example SC_CTOR(adder) is not how a typical constructor of a class looks like.
Personally, I'm not a big fan of macros, because if they blow up, it is hard to find the root-cause of the problem.
Or to quote the Google C++ Style Guide
(which will be our style guide btw) on how to name macro names: You're not really going to define a macro, are you?
This is why in the following, I'll try to avoid macros whenever it is possible. Luckily we can rearrange the same code to an equivalent with less macros:
structadder:publicsc_module{// module (class) declarationSC_HAS_PROCESS(adder);sc_in<int>a,b;// portssc_out<int>sum;voiddo_add(){// processsum.write(a.read()+b.read());//or just sum = a + b}adder(sc_module_namename):sc_module(name){// constructorSC_METHOD(do_add);// register do_add to kernelsensitive<<a<<b;// sensitivity list of do_add}};
But simply put: SystemC is just a C++ library for so-called discrete-event simulation (DES).
These kind of simulations can be used to model systems where events happen at discrete points in time (woooooosh).
For example, a traffic light could easily be modeled with SystemC.
You turn on different lights at discrete points in time and then turn them off again at another certain time.
Although implementing a traffic light is feasible with SystemC, the focus of SystemC is put on modeling digital circuits like CPUs, busses, memories, and so on.
So, all the stuff a Game Boy consists of!
Some years ago, SystemC was extended by the TLM library (Transaction-Level Modelling),
which basically allowed modeling on a higher abstraction level, thus increasing the simulation performance
and making things easier to code. The current version of TLM is 2; this is why the term SystemC TLM-2.0 is often used.
We'll just keep using "SystemC" as a term for "SystemC TLM-2.0" in the following.
A mentionable sidenote about SystemC is its
standardization
by the IEEE (Institute of Electrical and Electronics Engineers, basically the Jedi High Council of electrical engineers).
Many companies in the field of electronic system-level (ESL) design have adopted this standard.
Thus, knowing SystemC might look nice on your curriculum vitae!
In my personal oppinion, the best way to learn SystemC is to use it as most concepts are quite straight forward.
To get familar with it, I can really recommend the tutorials of Doulos and
asic-world. But you can also read a book like
SystemC: From the Ground Up if you want (I personally learned more from the tutorials).
The Game Boy - An Overview
In this section we'll take a look the at general design of the Game Boy from a high-level perspective.
Obviously we need to know what we want to model with SystemC before we start with the actual modeling.
So, let's take a look at the following image that provides a rough overview of the Game Boy's components:
1. Screen
A for today's standard super low-resolution, monochromatic LCD-screen with 160x144 pixels.
2. Joy Pad
8 buttons (left, right, top, bottom, A, B, START, SELECT) allow the user to control the Game Boy.
3. SoC (System on a Chip)
The heart of the Game Boy is a Sharp LR35902 SoC running at 4.19 MHz.
It crams multiple components such as CPU, PPU and APU into one chip.
4. CPU (Central Processing Unit)
The Game Boy uses a Sharp SM83 as its CPU.
It uses a modified version of the Z80 instruction set that will be explained in a following post.
Note, the CPU is often imprecisely referred to as "LR35902".
As you can see from the schematics and the bullet point above: LR35902 is the SoC, SM83 is the CPU which is a part
of the SoC.
5. PPU (Pixel Processing Unit)
Basically some kind of very basic graphics card that helps bringing the pixels on screen.
6. APU (Audio Processing Unit)
The APU creates the Game Boy's signature sound using different kinds sound devices such as pulse wave generators
or noise generators.
7. boot-ROM
A 256 Byte boot-ROM needed startup the Game Boy and verify the legal correctness of your cartridge.
The story behind the boot-ROM is actually quite interesting and will be highlighted in another post.
8. Serial I/O
Allows you to plugin a link cable and transfer Pokémon from A to B.
Besides these components there is also:
Cartridges
A cartridge is not just a simple memory to store your favorite game.
It can extend the RAM and uses interesting methods to circumvent the Game Boy's small address space.
Memories
The Game Boy has multiple memories to achieve different things. There's a VRAM to store pixel data,
a general-purpose RAM for computations, and there aforementioned boot-ROM that initializes the Game Boy on start up.
Timer
Internal timer that can be used to generate interrupts at regular intervals, for example to measure time.
DMA Controller
Short for Direct Memory Access Controller.
It's some very basic processing unit that only serves the purpose of shoveling data from A to B.
As you can, see there are quite a few components to model!
And indeed, coding a Game Boy emulator isn't something you accomplish in one afternoon (telling from my own experience).
The reference implementation (gbemu) I use is written in 4,500 SLoC (Software Lines of Code) and it even skips
some parts like the APU.
Assuming you are some kind of god programmer hitting 100 SLoC per hour, then you still need one week of coding!
Nevertheless, the modularity of the Game Boy makes it easy to split the implementation into multiple independent parts.
And there are already a lot of things that can be achieved by implementing a subset of the components listed above.
For instance, booting up the Game Boy (the part where the Nintendo logo scrolls down) doesn't need an APU, a timer, or serial I/O.
This makes programming an emulator a pleasant project where you can enjoy a sense of achievement every now and then!
In fact, seeing the Nintendo logo scroll down for the first time invoked a feeling of success that I had never felt before
in my coding career 😀.
Let's get started
The way I want to structure this project is by writing several posts covering the single components of the Game Boy.
Here's an overview I of posts that I want to write and that I've written so far:
Even though are listed in some order, it's more like a recommendation.
As you can see I recommend to start with the CPU, so let's get started with it!.
]]>
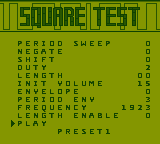


















 : A boomerang that can be used as a weapon.
: A boomerang that can be used as a weapon. : A double banana that can be used as a weapon.
: A double banana that can be used as a weapon. : Collect Mowgli’s head to get an extra life.
: Collect Mowgli’s head to get an extra life. : Gives some extra time when collected (1 minute in normal, 2 minutes in practice).
: Gives some extra time when collected (1 minute in normal, 2 minutes in practice). : If you collect the shovel, there will be a bonus level before the next level to collect additional items.
: If you collect the shovel, there will be a bonus level before the next level to collect additional items. : Activates a checkpoint when walking through the flower.
: Activates a checkpoint when walking through the flower. : Collect gems to beat a level.
: Collect gems to beat a level. : Fills up your health bar when collected.
: Fills up your health bar when collected. : Can only be collected in the bonus level. Grants an additional continue.
: Can only be collected in the bonus level. Grants an additional continue. : Grants invulnerability if selected as a weapon.
: Grants invulnerability if selected as a weapon. : Just gives some extra points.
: Just gives some extra points. : Stones that can be used as a weapon.
: Stones that can be used as a weapon.
























































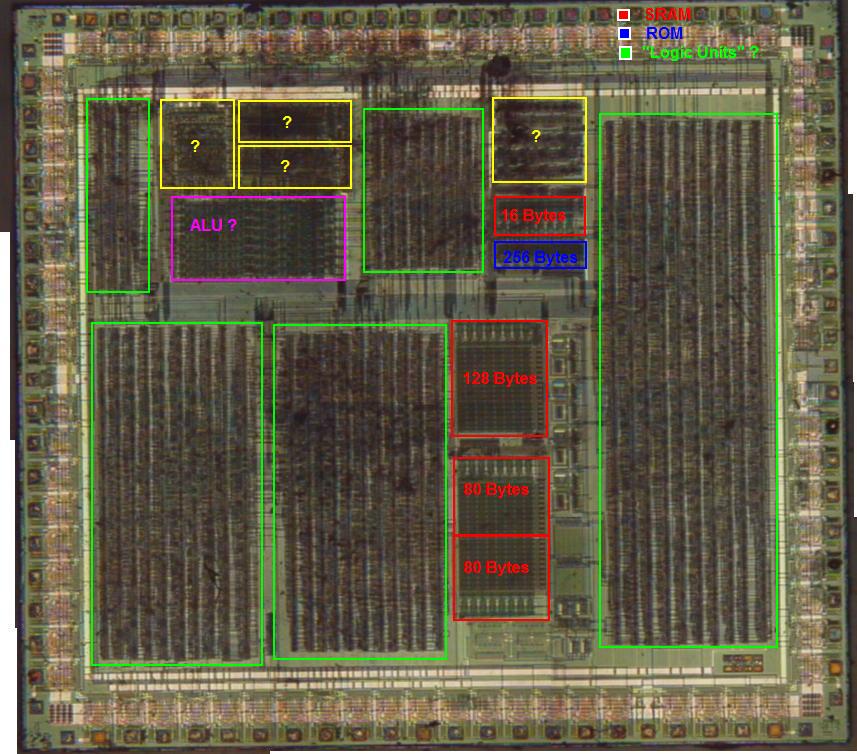




{kind=link}